由于官方文档过于简洁,所以记一下 CAMEL-AI 多智能体框架使用笔记,包括基础 Agent 使用(Prompt、Message、Memory、Tool),role-playing(角色扮演)使用、Workforce(多智能体协作)使用、RAG
1. CAMEL-AI 介绍
官网是这么介绍的:
CAMEL‑AI is an open‑source, modular framework for building intelligent multi‑agent systems.
CAMEL-AI 是一个开源的模块化框架,用于构建智能多智能体系统。
可以看到这个框架主打的是多智能体,我也是很看好多智能体的发展,多智能体可以分工合作,像团队成员一样协作完成复杂任务,每个智能体专注于一个子任务,相对来说对模型性能要求会低一些,而且可以并行跑(对于没有依赖的子任务)。
因为有一些复杂场景很难靠一个“超级智能体”解决,多智能体系统更现实而且更稳定和灵活。
2. Agent 基础组件及使用
Agent 是可以感知环境并在环境中自主行动以实现特定目标的系统。
当我们创建 Agent 时,需要关心以下几部分:
- Models:Agent 的大脑,负责处理输入数据和输出数据
- Message:Agent 和外界的通信方式,都通过 Message 来通信
- Prompt:定义 Agent 身份的重要手段,通过 Prompt 可以定义 Agent 的角色以及约束 Agent 的输出结构等等
- Memory:Agent 的关键组件,主要功能是存储和检索信息,达到“人脑”的效果,agent 可以根据过去的经验进行推理和决策
- Tools:这个是 Agent 操作外部世界的桥梁,通过 Tools, Agent 真正的对外部世界进行实际影响,比如说创建文件、网络搜索等等
下面就依次介绍这些组件的使用,最后完成一个使用到所有组件的 Agent
2.1 Models
创建模型是通过模型工厂类来创建
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url="https://api-inference.modelscope.cn/v1/",
api_key=api_key,
model_config_dict={"temperature": 0.2, "max_tokens": 4096},
)主要是这么几个参数:
- model_platform:模型所属平台,类似于 LangChain 里面的 provider
- model_type:具体的模型名称
- url:如果用的是 OPENAI_COMPATIBLE_MODEL 这种 OpenAI API 兼容的模型平台,需要自己定义 url
- api_key:从平台申请的 api key
- model_config_dict:这个可以添加模型的额外配置参数
2.2 Message
Agent 与外界沟通都是走的 Message。
在 CAMEL-AI 中,是基于一个BaseMessage 来通信的
message = BaseMessage(
role_name="example_user",
role_type=RoleType.USER,
content="Hello, CAMEL!",
meta_dict={}
)参数:
- role_name:角色名称,这个通过角色名称来看消息来源的,debug 方便
- role_type:真正觉得消息所属角色,RoleType.USER 和 RoleType.ASSISTANT
- content:消息内容,一般是文本
- meta_dict:消息元数据
多模态消息:比如我们想要发送给 llm 图片或者视频,怎么发送呢?总不能发送 content 吧,下面消息也可以是多模态的:
# send image
# 下载一张图片并创建一个 PIL Image 对象
url = "https://raw.githubusercontent.com/camel-ai/camel/master/misc/logo_light.png"
response = requests.get(url)
img = Image.open(BytesIO(response.content))
# 创建包含图片的用户消息
image_message = BaseMessage(
role_name="User_with_image",
role_type=RoleType.USER,
content="Here is an image",
meta_dict={},
image_list=[img] # 将图片列表作为参数传入
)
print(image_message)
# send video
# 读取本地视频文件
video_path = "./data/video.mp4"
with open(video_path, "rb") as video_file:
video_bytes = video_file.read()
# 创建包含视频的用户消息 make_user_message 可以不用指定 role type 了,直接创建用户消息
user_msg = BaseMessage.make_user_message(
role_name="User",
content="请描述这段视频的内容",
video_bytes=video_bytes, # 将视频字节作为参数传入
)每次指定 role type 很麻烦,所以也有直接创建指定角色消息的方法:
# 创建用户消息
user_msg = BaseMessage.make_user_message(
role_name="User_1",
content="Hi, what can you do?"
)
# 创建助手消息
assistant_msg = BaseMessage.make_assistant_message(
role_name="Assistant_1",
content="I can help you with various tasks."
)2.3 Prompt
提示词一般使用就是定义预先写好的设置,然后里面放几个变量,通过实际情况替换后传给 llm 处理。
基本使用:
# 也可以像langchain一样,自定义prompt模版
prompt = TextPrompt("你好,我的名字是{user_name},我来自{user_location},请问你是谁?")
print(prompt)
# 可以打印参数列表
print(prompt.key_words)
# 可以全部赋值
print(prompt.format(user_name="小明", user_location="北京"))
# 也可以部分赋值
print(prompt.format(user_name="小明"))
# output
你好,我的名字是{user_name},我来自{user_location},请问你是谁?
{'user_location', 'user_name'}
你好,我的名字是小明,我来自北京,请问你是谁?
你好,我的名字是小明,我来自{user_location},请问你是谁?提示词优化:
一般来说,用户给的提示词不会那么的正规,所以程序里要对用户的提示词进行一些优化更好的完成任务,最常用的就是思维链的思路,把目标任务进行拆解,然后给llm思考执行,比直接给llm目标任务要容易完成的多,下面是思维链的使用方式:
主要是用框架里的TaskSpecifyAgent 这个agent进行提示词的优化工作:
# 提示词自动优化,就是让任务更加的确切
from camel.agents import TaskSpecifyAgent
from camel.types import TaskType
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url="https://api-inference.modelscope.cn/v1/",
api_key=api_key,
)
task_specify_agent = TaskSpecifyAgent(
model=model, task_type=TaskType.AI_SOCIETY, output_language="zh-cn"
)
cot_prompt = task_specify_agent.run(
task_prompt="如何开发一个支持高并发的程序?",
meta_dict=dict(assistant_role="架构师", user_role="开发者"),
)
cot_prompt
# output
'如何设计并实现一个能够处理每秒10万次请求的高并发Web应用程序,确保低延迟和高可用性?'
----------------------------
## 自定义prompt
from camel.prompts import TextPrompt
custom_prompt = TextPrompt(
"这是一个任务:我是一名{occupation},我想完成的任务是:{task},请你制定完成这个任务所需的任务步骤!"
)
custom_specify_agent = TaskSpecifyAgent(
model=model, output_language="zh-cn", task_specify_prompt=custom_prompt
)
response = custom_specify_agent.run(
task_prompt="如何开发一个支持高并发的程序?",
meta_dict=dict(occupation="初级程序员"),
)
response
# output
'要成为一名能够开发支持高并发程序的初级程序员,你可以按照以下步骤来逐步提升自己的技能和知识:\n\n1. **理解高并发的基本概念**:\n - 学习什么是并发和并行。\n - 了解高并发系统的特点及挑战,如锁争用、内存溢出等。\n\n2. **掌握一门或多门编程语言**:\n - 选择一门适合开发高并发应用的语言,如Java、Go或Python。\n - 深入学习这门语言的并发模型和多线程处理机制。\n\n3. **学习并发控制技术**:\n - 理解同步与异步的概念。\n - 掌握常见的并发控制工具和技术,例如互斥锁(Mutex)、信号量(Semaphore)、条件变量(Condition Variable)等。\n\n4. **研究高并发框架和库**:\n - 探索一些流行的高并发处理框架,如Netty、Akka等。\n - 学习使用这些框架来简化并发编程。\n\n5. **性能优化技巧**:\n - 学习如何进行代码层面的优化,比如减少锁的竞争。\n - 了解硬件层面的知识,如CPU缓存的工作原理,以优化数据访问模式。\n\n6. **实践项目经验**:\n - 尝试参与或自己动手实现一些小规模的并发项目。\n - 分析现有高并发系统的架构设计,理解其背后的原理。\n\n7. **测试与调试**:\n - 学会编写单元测试和集成测试,确保并发逻辑正确无误。\n - 使用专业的工具进行压力测试,模拟高负载情况下的系统表现。\n\n8. **持续学习和跟进新技术**:\n - 关注行业动态和技术论坛,了解最新的并发处理技术和趋势。\n - 不断实践新的想法和技术,保持技术的前沿性。\n\n通过上述步骤的学习和实践,你将逐渐建立起开发高效、稳定高并发应用程序的能力。每一步都需要时间和耐心去探索和实践,但只要你坚持不懈,最终定能达成目标。'2.4 Memory
个人认为,记忆里面,CAMEL 最方便使用的就是 LongtermAgentMemory 这个长期 Agent 记忆组件,它可以通过对话记录+向量数据库中获取上下文,最大程度不丢失记忆:
from camel.embeddings import OpenAICompatibleEmbedding
from camel.memories import (
ChatHistoryBlock,
LongtermAgentMemory,
MemoryRecord,
ScoreBasedContextCreator,
VectorDBBlock,
)
from camel.types import ModelType, OpenAIBackendRole
from camel.utils import OpenAITokenCounter
load_dotenv()
siliconflow_api_key = os.getenv("SILICONFLOW_API_KEY")
# 嵌入模型 用国内的硅基流动 兼容OpenAI的格式 不占用本地资源
embedding = OpenAICompatibleEmbedding(
model_type="BAAI/bge-m3",
url="https://api.siliconflow.cn/v1",
api_key=siliconflow_api_key,
)
# 必须需要先调用embed_list方法来确定输出维度
embedding.embed_list(["Hello, world!"])
# 初始化基于内存的记忆
# 三部分
# 1. context 从 chat_history 获取上下文,由于模型有输入token的限制,所以会有一个权重衰减策略
# 2. chat_history_block 基于kv的聊天历史记忆模块
# 3. vector_db_block 基于向量数据库的语义记忆模块
chat_history_block = ChatHistoryBlock()
vector_db_block = VectorDBBlock(embedding=embedding)
memory = LongtermAgentMemory(
context_creator=ScoreBasedContextCreator(
token_counter=OpenAITokenCounter(ModelType.GPT_4O_MINI),
token_limit=1024,
),
chat_history_block=chat_history_block,
vector_db_block=vector_db_block,
)
# 2. 创建记忆记录
records = [
MemoryRecord(
message=BaseMessage.make_user_message(
role_name="User", content="什么是CAMEL AI?"
),
role_at_backend=OpenAIBackendRole.USER,
),
MemoryRecord(
message=BaseMessage.make_assistant_message(
role_name="Agent",
content="CAMEL-AI是第一个LLM多智能体框架,并且是一个致力于寻找智能体 scaling law 的开源社区。",
),
role_at_backend=OpenAIBackendRole.ASSISTANT,
),
]
# 写入记忆
memory.write_records(records)
# 会同时写入到 chat_history_block + vector 向量库
recent_records = chat_history_block.retrieve(window_size=3)
for record in recent_records:
print(
f"ChatHistoryBlock 消息: {record.memory_record.message.content}, 权重: {record.score}"
)
vector_records = vector_db_block.retrieve(keyword="CAMEL AI?", limit=3)
for record in vector_records:
print(
f"VectorBlock 消息: {record.memory_record.message.content}, 权重: {record.score}"
)
context, token_count = memory.get_context()
print(f"Context: {context}")
print(f"Token Count: {token_count}")
# 输出
ChatHistoryBlock 消息: 什么是CAMEL AI?, 权重: 0.81
ChatHistoryBlock 消息: CAMEL-AI是第一个LLM多智能体框架,并且是一个致力于寻找智能体 scaling law 的开源社区。, 权重: 0.9
VectorBlock 消息: 什么是CAMEL AI?, 权重: 0.8989381070891671
VectorBlock 消息: CAMEL-AI是第一个LLM多智能体框架,并且是一个致力于寻找智能体 scaling law 的开源社区。, 权重: 0.682588891918595
Context: [{'role': 'user', 'content': '什么是CAMEL AI?'}, {'role': 'assistant', 'content': 'CAMEL-AI是第一个LLM多智能体框架,并且是一个致力于寻找智能体 scaling law 的开源社区。'}]
Token Count: 52LongtermAgentMemory 有三个关键参数:
- context_creator:创建context的对象,memory.get_context() 会直接这么获取最近的记忆信息给 llm,就是这个 creator 创建的
- chat_history_block:基于kv的聊天历史记忆模块,存储的是原始聊天记录文本
- vector_db_block:基于向量库的向量存储模块,存储的是嵌入向量
使用效果:
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url="https://api-inference.modelscope.cn/v1/",
api_key=api_key,
)
agent = ChatAgent(
model=model,
output_language="zh-cn",
system_message="你是一个AI助手,你的任务是帮助用户完成任务",
)
# 可以先注释 再打开 看看加不加记忆的区别
agent.memory = memory
response = agent.step("我们刚刚说的什么来着?")
print(response.msgs[0].content)
# output
我们刚才讨论了CAMEL AI,它是第一个大型语言模型(LLM)多智能体框架,并且是一个致力于寻找智能体扩展定律(scaling law)的开源社区。这个框架允许不同的AI智能体相互协作和竞争,以完成复杂任务或探索新的应用场景。如果您有更多关于CAMEL AI的问题或需要进一步的信息,请随时告诉我!2.5 Tool
工具有框架的预设工具,也可以自己自定义工具
2.5.1 自定义工具
自定义工具,其实就是写一个方法(一定要注意注释要写好点,llm调用工具全靠注释),然后用FunctionTool包装一下这个自定义方法,就做好工具了,可以直接给 Agent 使用:
# 关于工具的定义、初始化、以及给agent调用
import math
from camel.toolkits import FunctionTool
agent = ChatAgent(
model=model,
output_language="zh-cn",
system_message="你是一个AI女仆,你的任务是帮助主人完成任务",
)
response = agent.step("2的平方根是多少?")
# 不带工具,精度不会很精确:2的平方根大约是1.414。
print(f"不带工具:{response.msgs[0].content}")
# 定义一个算平方根的工具
def sqrt_function(x: float) -> float:
"""计算一个数的平方根。
Args:
x (float): 需要计算平方根的数字
Returns:
float: 平方根计算结果
"""
return math.sqrt(x)
# 使用工具包装一下
sqrt_tool = FunctionTool(sqrt_function)
# 打印一下工具的参数
print(f"工具名称: {sqrt_tool.get_function_name()}")
print(f"工具描述: {sqrt_tool.get_function_description()}")
print(f"工具参数: {sqrt_tool.get_openai_function_schema()}")
# 初始化一个带代理的工具
agent = ChatAgent(
model=model,
output_language="zh-cn",
system_message="你是一个AI女仆,你的任务是帮助主人完成任务",
tools=[sqrt_tool], # 将工具添加到代理中
)
# 现在再次调用代理
response = agent.step("2的平方根是多少?")
# 带工具,精度会更高
print(f"带工具:{response.msgs[0].content}")
# output
不带工具:2的平方根大约是1.414。
工具名称: sqrt_function
工具描述: 计算一个数的平方根。
工具参数: {'name': 'sqrt_function', 'description': '计算一个数的平方根。', 'strict': True, 'parameters': {'properties': {'x': {'type': 'number', 'description': '需要计算平方根的数字'}}, 'required': ['x'], 'type': 'object', 'additionalProperties': False}}
带工具:2的平方根是1.4142135623730951。2.5.2 预设工具
CAMEL 预设了一些工具,可以查看camel.toolkits 这个包里面,都是预设的工具,下面是用维基百科工具演示:
from camel.models import ModelFactory
from camel.societies import RolePlaying
from camel.toolkits import MathToolkit, SearchToolkit
from camel.types.agents import ToolCallingRecord
from camel.utils import print_text_animated
from colorama import Fore
# init search and math toolkits
tools_list = [*SearchToolkit().get_tools(), *MathToolkit().get_tools()]
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url="https://api-inference.modelscope.cn/v1/",
api_key=api_key,
)
agent = ChatAgent(model=model, tools=tools_list, output_language="zh-cn")
response = agent.step(
input_message="用维基百科查查牛津大学是什么时候成立的,有没有准确的成立日期呢?"
)
response
# 输出 可以在 response 中看到 ToolCallingRecord 就是工具的调用记录,调用了 search_wiki 工具
ChatAgentResponse(msgs=[BaseMessage(role_name='Assistant', role_type=<RoleType.ASSISTANT: 'assistant'>, meta_dict={}, content='牛津大学是位于英格兰牛津的一所学院研究型大学。有记录显示,早在1096年这里就有教学活动,这使得牛津大学成为英语世界中最古老的大学,也是全球第二古老的持续运营的大学。1167年,亨利二世禁止英国学生前往巴黎大学就读,此后牛津大学迅速扩大。当学生与牛津镇民发生纠纷时,一些牛津学者逃到了东北方向的剑桥,在那里于1209年建立了剑桥大学。两所英国古老大学有许多共同点,通常被统称为“牛桥”。\n\n不过关于具体的成立日期,牛津大学并没有一个确切的成立日,因为它是逐步发展起来的。但通常认为1096年左右是其开始教学的时间。', video_bytes=None, image_list=None, image_detail='auto', video_detail='low', parsed=None)], terminated=False, info={'id': 'chatcmpl-6f91ae30-20bd-9100-9920-1abb591844fc', 'usage': {'completion_tokens': 168, 'prompt_tokens': 3617, 'total_tokens': 3785, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'termination_reasons': ['stop'], 'num_tokens': 248, 'tool_calls': [ToolCallingRecord(tool_name='search_wiki', args={'entity': '牛津大学'}, result='There is no page in Wikipedia corresponding to entity 牛津大学, please specify another word to describe the entity to be searched.', tool_call_id='call_62d33f3b17094cd9bcc606'), ToolCallingRecord(tool_name='search_wiki', args={'entity': 'University of Oxford'}, result='The University of Oxford is a collegiate research university in Oxford, England. There is evidence of teaching as early as 1096, making it the oldest university in the English-speaking world and the second-oldest continuously operating university globally. It expanded rapidly from 1167, when Henry II prohibited English students from attending the University of Paris. When disputes erupted between students and the Oxford townspeople, some Oxford academics fled northeast to Cambridge, where they established the University of Cambridge in 1209. The two English ancient universities share many common features and are jointly referred to as Oxbridge.', tool_call_id='call_9f4558bd25af46338c9f15')], 'external_tool_call_requests': None})2.6 综合使用
写一个可以多轮对话的 agent demo,并且可以进行维基百科搜索,也有记忆功能
import os
from camel.agents import ChatAgent, TaskSpecifyAgent
from camel.embeddings import OpenAICompatibleEmbedding
from camel.memories import (
ChatHistoryBlock,
LongtermAgentMemory,
ScoreBasedContextCreator,
VectorDBBlock,
)
from camel.models import BaseModelBackend, ModelFactory
from camel.prompts import TextPrompt
from camel.responses import ChatAgentResponse
from camel.toolkits import FunctionTool, SearchToolkit
from camel.types import ModelPlatformType, ModelType, TaskType
from camel.utils import OpenAITokenCounter
from dotenv import load_dotenv
load_dotenv()
modelscope_api_key: str | None = os.getenv("MODELSCOPE_SDK_TOKEN")
siliconflow_api_key: str | None = os.getenv("SILICONFLOW_API_KEY")
model: BaseModelBackend = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url="https://api-inference.modelscope.cn/v1/",
api_key=modelscope_api_key,
)
# prompt specify
custom_specify_agent: TaskSpecifyAgent = TaskSpecifyAgent(
model=model, output_language="zh-cn", task_type=TaskType.AI_SOCIETY
)
# define memory
embedding: OpenAICompatibleEmbedding = OpenAICompatibleEmbedding(
model_type="BAAI/bge-m3",
url="https://api.siliconflow.cn/v1",
api_key=siliconflow_api_key,
)
# 必须需要先调用embed_list方法来确定输出维度
embedding.embed_list(["Hello, world!"])
chat_history_block = ChatHistoryBlock()
vector_db_block = VectorDBBlock(embedding=embedding)
memory = LongtermAgentMemory(
context_creator=ScoreBasedContextCreator(
token_counter=OpenAITokenCounter(ModelType.GPT_4O_MINI),
token_limit=1024,
),
chat_history_block=chat_history_block,
vector_db_block=vector_db_block,
)
# tool
search_toolkit = SearchToolkit()
tool_list: list[FunctionTool] = [
FunctionTool(search_toolkit.search_wiki),
]
# agent 指定 model tool memory
agent: ChatAgent = ChatAgent(
model=model, output_language="zh-cn", tools=tool_list, memory=memory
)
def main() -> None:
print("请输入内容,输入 'exit' 退出。")
while True:
user_input = input("你:")
if user_input.strip().lower() == "exit":
print("已退出。")
break
# 提示词优化
prompt_response: TextPrompt = custom_specify_agent.run(user_input)
print(f"优化后的提示词:{prompt_response}")
response: ChatAgentResponse = agent.step(prompt_response)
print("助手:", response.msg.content)
if __name__ == "__main__":
main()3. 核心特性
上面的功能,一般 LLM 应用框架都会有这些功能,CAMEL 的核心功能就是多个 Agent 之间的相互协调合作的封装,下面是两个很有意思的功能:role-playing 角色扮演 和 workforce 团队合作引擎
3.1 RolePlaying
RolePlaying 就是实际用户先提出一个 task,两个 AI,一个 AI 扮演用户,一个 AI 扮演助手,“用户”根据给定task不断的提需求,“助手”就不断的完成,用户AI 不断的判断是否完成 task 要求,通过自动化多轮对话完成我们给出的 task。
主要用到 RolePlaying 类,下面是几个重要参数:
- task_prompt:我们实际想要完成的任务
- with_task_specify:这个是让我们选择是否需要任务具体化,就是更确切一点的提示词优化
- task_specify_agent_kwargs:提示词优化的 agent 参数
- assistant_role_name:AI 助手的角色名称
- assistant_agent_kwargs:AI 助手的 agent 参数
- user_role_name:AI 用户的角色名称
- user_agent_kwargs:AI 用户的 agent 参数
- critic_role_name:设置为 human,就会在对话过程中让认为参与,选择下一步的动作
- with_critic_in_the_loop:设置为 True 之后,critic_role_name 就会生效,对话支持人为打断功能
from camel.models import ModelFactory
from camel.societies import RolePlaying
from camel.types import ModelPlatformType
# 初始化model
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url="https://api-inference.modelscope.cn/v1/",
api_key=modelscope_api_key,
)
# role playing 主要配置三类参数
# 1. 要执行什么任务,任务是否需要 specify 就是任务需不需让 AI 描述的更清晰具体
# 2. 执行者 agent的身份、模型配置
# 3. 用户agent的身份、模型配置
society = RolePlaying(
# task config
task_prompt="你怎么看待关于 AI 在未来的发展?",
with_task_specify=True,
task_specify_agent_kwargs=dict(model=model),
# assistant agent config
assistant_role_name="AI 专家",
assistant_agent_kwargs=dict(model=model),
# user agent config
user_role_name="对 AI 感兴趣的创业者",
user_agent_kwargs=dict(model=model),
# 可以在对话中人为选择,人为优先干预
critic_role_name="human",
with_critic_in_the_loop=True,
)
# 初始化第一条消息
input_msg = society.init_chat()
max_chat = 10
for _ in range(max_chat):
assistant_response, user_response = society.step(input_msg)
if assistant_response.terminated:
print(
f"助手 agent 已终止,原因:{assistant_response.info['termination_reasons']}"
)
if user_response.terminated:
print(f"用户 agent 已终止,原因:{user_response.info['termination_reasons']}")
# 获取执行结果
print(f"用户 agent 输出内容:{user_response.msg.content}")
if "CAMEL_TASK_DONE" in user_response.msg.content:
break
print(f"助手 agent 输出内容:{assistant_response.msg.content}")
input_msg = assistant_response.msg3.2 Workforce
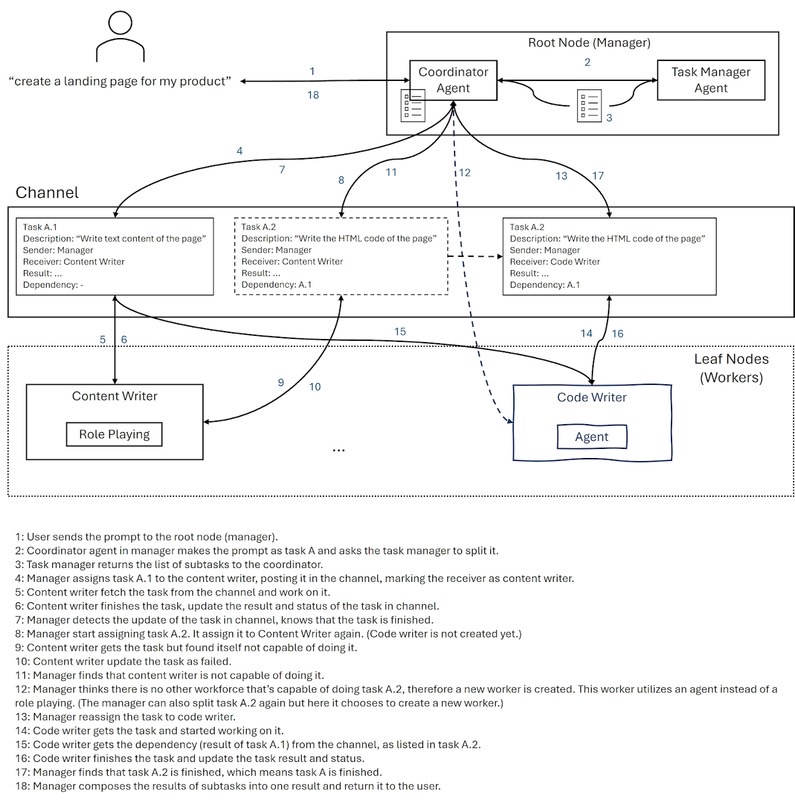
RolePlaying 只是小打小闹,这个才是真正的多智能体!有三个重要角色:
- 协调者 Agent :项目经理,协调整体任务的把控执行
- 任务拆解 Agent:战略主管,将一个大型的作业,拆分为较小的,可行的子任务
- 执行者 Agent(可以多个):打工人,真正做任务的 AI,可以是一个 RolePlaying Agent,每个 Agent 都有自己的功能,比如说 WebSearchAgent,IntentAgent 等等
用户输入任务 -》 协调者 Agent -》 任务分解者 Agent -》 任务计划 -》 协调者 Agent 根据任务计划分发给不同的执行者 Agent 做
可以参考下面图片:
具体 demo, 做一个旅行规划的多 Agent 应用:
- 创建 Workforce 实例
- description:Workforce 描述
- new_worker_agent_kwargs:worker agent 创建的参数
- coordinator_agent_kwargs:协调者 agent 创建参数
- task_agent_kwargs:任务拆解者 agent 参数
- 创建搜索 agent
- 创建做旅行计划的 agent
- 创建做攻略评估的 agent
- 将这三个 agent 添加到 workforce 作为 worker,添加的时候这个描述一定要精准且易读,因为全靠这个描述选择用哪个 agent
- 实例化一个 task
- workforce 执行这个 task
- 输出 task 结果
# 简单 demo,做一个旅行规划的多 Agent 应用
import nest_asyncio
from camel.agents import ChatAgent
from camel.societies.workforce import Workforce
from camel.tasks import Task
from camel.toolkits import FunctionTool, SearchToolkit
load_dotenv()
model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-max",
api_key=os.getenv("BAILIAN_API_KEY"),
)
# 创建 workforce 实例
workforce = Workforce(
description="旅游攻略制作与评估工作组",
# 这三个参数不是必须,但是最好明确的自定义 worker 初始化参数 协调者参数 任务拆解者参数
new_worker_agent_kwargs=dict(model=model),
coordinator_agent_kwargs=dict(model=model),
task_agent_kwargs=dict(model=model),
)
# 搜搜工具
search_tool = FunctionTool(SearchToolkit().search_baidu)
# 搜索 agent
search_agent = ChatAgent(
system_message="""你是一个专业的旅游信息搜索助手。你的职责是:
1. 搜索目的地的主要景点信息
2. 搜索当地特色美食信息
3. 搜索交通和住宿相关信息
请确保信息的准确性和实用性。""",
model=model,
tools=[search_tool],
output_language="zh-cn",
)
# 做计划的 agent
planner_agent = ChatAgent(
system_message="""你是一个专业的旅行规划师。你的职责是:
1. 根据景点分布规划合理的游览顺序
2. 为每天安排适量的景点和活动
3. 考虑用餐、休息等时间
4. 注意不同季节的特点
请确保行程安排合理且具有可行性。""",
model=model,
output_language="zh-cn",
)
# 评估攻略的agent
reviewer_agent = ChatAgent(
system_message="""你是一个经验丰富的旅行爱好者。你的职责是:
1. 从游客角度评估行程的合理性
2. 指出可能的问题和改进建议
3. 补充实用的旅行小贴士
4. 评估行程的性价比
请基于实际旅行经验给出中肯的建议。""",
model=model,
output_language="zh-cn",
)
# 添加工作节点 可以链式调用,这里的描述一定要精准且易读,因为协调者就是根据这个描述来分发任务的
workforce.add_single_agent_worker(
"负责搜索目的地相关信息", worker=search_agent
).add_single_agent_worker(
"负责制定详细行程规划", worker=planner_agent
).add_single_agent_worker("负责从游客角度评估行程", worker=reviewer_agent)
# 实例化一个task id 可以是任意字符串
task = Task(
content="规划一下从北京周五晚上到青岛,周日晚上从青岛回北京,周末两天游玩青岛的行程安排",
id="0",
)
nest_asyncio.apply()
# 让 Workforce 处理这个任务
task = workforce.process_task(task)
print(task.result)输出内容:
Worker node 12932904944 (负责搜索目的地相关信息) get task 0.0: 搜索青岛的旅游景点、美食和住宿信息,并提供给负责制定详细行程规划的同事。<ID>: 12932904944
Warning: No results found. Check if Baidu HTML structure has changed.
======
Reply from Worker node 12932904944 (负责搜索目的地相关信息):
以下是关于青岛旅游的相关信息,供您参考以制定详细的行程规划:">\\[青岛旅游景点\\n1. **[青岛旅游景点攻略_青岛打卡/必去景点大全/排名/推荐【携程攻略】](http://www.baidu.com/link?url=sXCy5mSbN8sDFc73MI1gzp4gKuoEA_iit4HV6_3idTZfPRDgaQID2AXnrNogkAxHA598QiWvsfc4Gsop0_JLH_)**\\n- 该链接提供了详尽的青岛旅游景点介绍,包括热门打卡地、必去景点以及游客评价和建议。\\n\\n### 青岛特色美食\\n- 对于青岛特色美食的信息搜索暂时没有返回具体结果。不过通常来说,青岛以其海鲜闻名,比如烧烤鱿鱼、海蛎煎饼等都是当地非常受欢迎的美食。此外,青岛啤酒也是不可错过的体验之一。建议进一步查询或访问当地的美食街和餐馆来获取更准确的信息。\\n\\n### 青岛住宿推荐\\n1. **[青岛住宿推荐!靠近栈桥,不想走](http://www.baidu.com/link?url=lqaFpZ4F9RBoojTcFQxCt_5NPyj-T09B8P91PPpG8fbH446XW4ilVtWoGSOQyBHpguLC9r9XiU0Z_axyMCKCV59s5QYtpYmv_vLYUPrp3o75-IPQM0oG3PIjTZ_Ris5L)**\\n- 这个链接提供了一些靠近著名景点如栈桥附近的住宿选择,方便出行游览。\\n2. **[青岛酒店预订,价格查询-青岛宾馆住宿信息-【携程旅行手机版】](http://www.baidu.com/link?url=zkuj6F8Ou34w6_YfVjeOqSR2M50XxEnwttx2pk4EvVhXV6GP2sBncpxF4YN3gVT9cEu9WuitmAsYUL1ff-O7Va)**\\n- 通过携程旅行平台可以查询并预订各类酒店,同时比较不同住宿的价格和服务,帮助找到最适合您的住处。\\n请根据这些信息进行下一步的详细安排。如果需要更多特定类型的信息或者有其他要求,请随时告知我。
======Worker node 6245538816 (负责制定详细行程规划) get task 0.1: 根据收集到的信息,规划从北京周五晚上出发至青岛,周日晚上返回北京的具体行程安排,包括交通方式、游玩路线、餐饮及住宿等。<ID>: 6245538816
======
Reply from Worker node 6245538816 (负责制定详细行程规划):
### 青岛周末游行程规划(周五晚上出发,周日晚上返回北京)\n**交通方式:**">\\[从北京到青岛可以选择高铁或飞机。建议选择高铁,因为高铁站通常位于城市中心,方便前往住宿地点。根据实际购票情况,选择适合的车次。\\\\n- **周五晚上:** 晚上乘坐高铁从北京出发,预计到达青岛的时间为晚上10点左右。抵达后直接前往预订好的酒店休息。\\\\n- **周六:** \\\\n - 上午:参观栈桥,这里是青岛的标志性景点之一,可以欣赏到美丽的海景和青岛的历史建筑。之后步行至小青岛公园继续游览。\\\\n - 中午:在附近寻找一家海鲜餐厅享用午餐,品尝当地特色如烤鱿鱼、海蛎煎饼等。推荐尝试青岛啤酒。\\\\n - 下午:前往八大关风景区,这里有许多欧式建筑和美丽的街道非常适合拍照留念。随后可前往第一海水浴场放松身心。\\\\n - 晚餐:在市区内挑选一家评价较好的海鲜餐馆用餐。\\\\n- **周日:** \\\\n - 上午:访问青岛啤酒博物馆了解青岛啤酒的历史文化,并有机会品尝新鲜酿造的啤酒。\\\\n - 中午:在啤酒博物馆附近的餐厅享用午餐。\\\\n - 下午:如果时间允许的话,可以去五四广场散步,感受城市的现代气息。之后准备返程事宜。\\\\n - 晚上:乘高铁返回北京。\\\\n**餐饮及住宿建议:**">\n- 住宿:推荐选择靠近栈桥或者八大关景区的酒店,便于出行。可以通过携程等平台提前预订。\\\\n- 美食:除了上述提到的海鲜外,还可以尝试其他地方风味小吃。记得多喝几杯正宗的青岛啤酒!
======Worker node 6245540064 (负责从游客角度评估行程) get task 0.2: 从游客角度评估行程安排的合理性与吸引力,提出改进建议或确认行程安排是否合适。<ID>: 6245540064
======
Reply from Worker node 6245540064 (负责从游客角度评估行程):
从游客的角度来看,这个周末游青岛的行程安排是合理且具有吸引力的。交通方式选择高铁,方便快捷,尤其适合短途旅行。周五晚上出发,周日晚上返回北京,充分利用了周末时间。\\n周六的行程安排得当,包含了栈桥、小青岛公园等著名景点,以及八大关风景区和第一海水浴场,能够全面体验青岛的历史文化与自然风光。午餐和晚餐推荐品尝当地特色海鲜,这将为旅程增添更多乐趣。\\n周日参观青岛啤酒博物馆是一个很好的选择,让游客深入了解这座城市的文化背景。之后如果还有时间去五四广场散步也是不错的安排。\\n建议:\n1. 根据个人兴趣调整游览顺序或增加一些非主流但有趣的小众景点。\n2. 注意天气变化,提前查看目的地天气预报,以便适时调整户外活动计划。\n3. 预留足够的休息时间,避免行程过于紧凑导致疲劳。\n4. 尝试预订一些有特色的民宿来代替普通酒店,可能会给旅行带来不一样的体验。
======根据提供的信息和建议,从北京周五晚上出发至青岛,并于周日晚上返回北京的周末游行程可以这样规划:
### 交通
- **前往**:周五晚上乘坐高铁从北京出发前往青岛,预计到达时间为晚上10点左右。选择高铁是因为其便捷性及通常位于市中心的位置。
- **返回**:周日晚上同样通过高铁从青岛回到北京。
### 住宿
- 建议预订靠近主要景点如栈桥或八大关风景区附近的酒店,以方便出行。可以通过携程等在线平台提前预定合适的住处。
### 行程安排
- **周六**
- 上午:游览青岛标志性景点栈桥,随后步行至小青岛公园。
- 中午:在附近享用海鲜午餐,推荐尝试当地特色如烤鱿鱼、海蛎煎饼等,并品尝青岛啤酒。
- 下午:参观八大关风景区,欣赏欧式建筑;之后前往第一海水浴场放松身心。
- 晚餐:在市区内挑选一家评价较高的海鲜餐馆用餐。
- **周日**
- 上午:访问青岛啤酒博物馆了解啤酒文化并品尝新鲜酿造的啤酒。
- 中午:在啤酒博物馆周边享受午餐。
- 下午(如果时间允许):漫步五四广场,感受现代都市氛围。
- 准备返程。
### 额外建议
- 考虑到个人兴趣,可适当调整行程中景点的选择或顺序。
- 关注天气预报,适时调整户外活动计划。
- 确保行程中有足够的休息时间,避免过度劳累。
- 可以考虑入住具有特色的民宿来增加旅行的独特体验。
这个行程结合了青岛的历史文化与自然美景,同时也不失为一次美食之旅。希望这些建议能帮助您度过一个愉快而充实的周末!