关于 LangChain 的 ChatModels、PromptTemplate、RAG、Agent 相关组件介绍
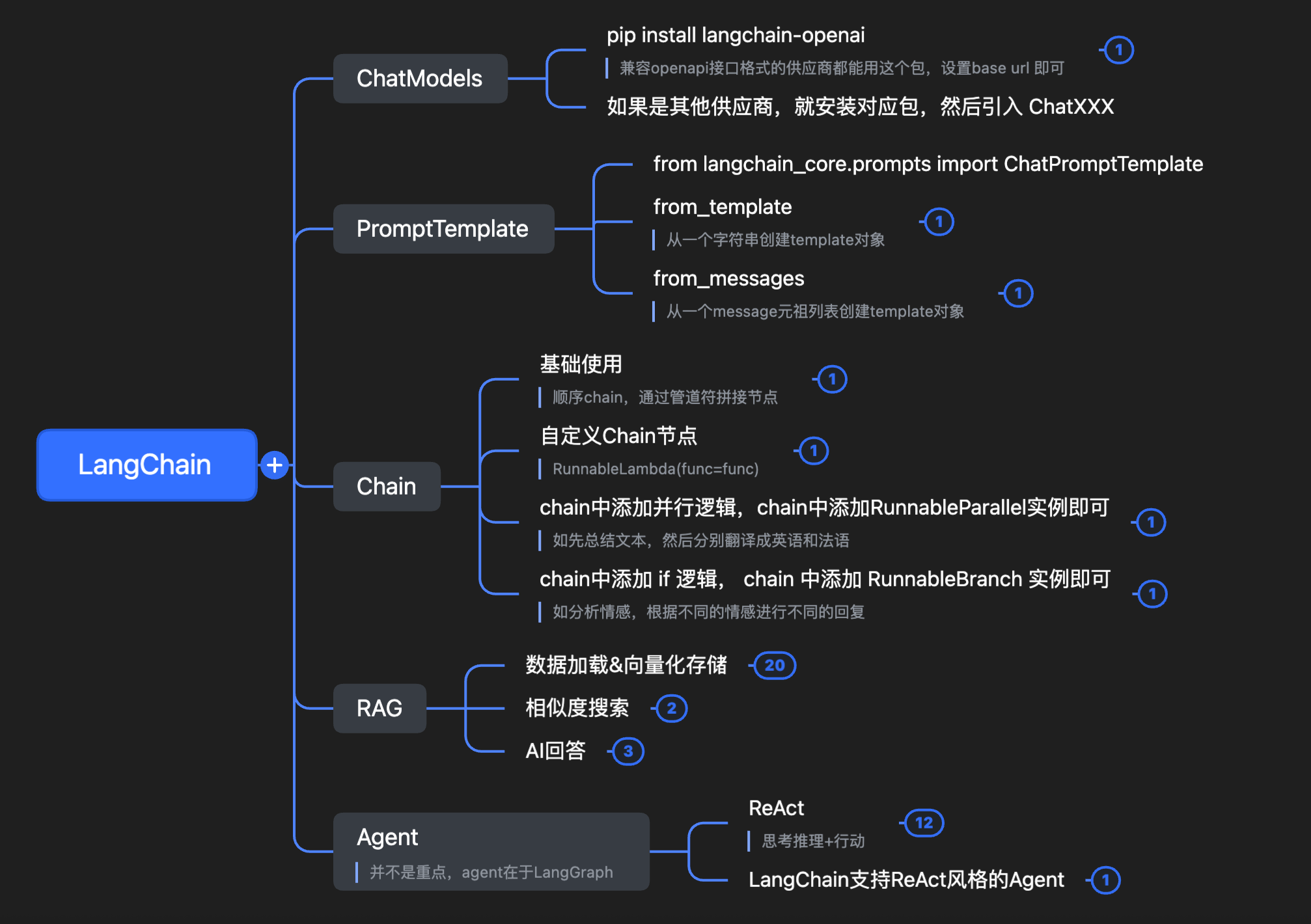
1. 整体介绍
LangChain 其实用途很简单,就是一个框架,让我们方便的构建基于大语言模型(LLM)的框架,让 LLM 可以方便的和外部数据、工具、逻辑结合,从而构建出功能更强,上下文更丰富的应用。
- 我们需要对接各个厂商的 LLM,所以就有了
ChatModels组件,想用哪个厂商的就 install 哪个厂商的包,然后 import 对应的 ChatXXX 类就行; - 我们需要写提示词(Prompt),所以就有了
PromptTemplate组件,可以写系统提示词,灵活替换变量; - 我们需要在 LLM 调用前后加一些逻辑,或者调用 A 模型处理 XXX,然后调用 B 模型处理 XXX,所以有了
Chain组件,把一次任务作为一个 workflow 串联起来; - 我们需要处理大模型幻觉问题,想用外部数据为大模型的知识做补充,所以有了
RAG; - RAG 需要加载文档、拆分文档,所以有了各种
XXXLoader组件,也提供了各种XXXSplitter; - 加载拆分好的文档,需要方便的根据问题进行相似度搜索,所以 LangChain 又提供了各种向量库的集成(存储 & 相似度搜索)以及
Embeddings模型的集成; - 我们需要 LLM 自行思考行动,所以 LangChain 也提供了 Agent 支持,并且可以很方便的初始化一个 ReAct 模式的 Agent。
2. ChatModels

2.1 基本使用
其实做通用的就是 ChatOpenAI 类,也就是安装 langchain-openai 依赖包,这个 ChatOpenAI 就是兼容 OpenAI API 风格的厂商接口,现在大部分厂商都会提供 OpenAI API 风格的接口比如硅基流动、魔塔等等。
下面是国内可用的方案,用硅基流动的 api 来跑通 LLM 请求逻辑(需要在 .env 文件中写入 OPENAI_API_KEY 变量):
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv()
# 兼容 openai api 的服务商都能用 ChatOpenAI
# 要设置 OPENAI_API_KEY 环境变量
model = ChatOpenAI(
model="Qwen/Qwen2.5-72B-Instruct", base_url="https://api.siliconflow.cn/v1"
)
# 如果想选择其他供应商的模型
# https://python.langchain.com/docs/integrations/providers/
# 基本用下来就是 ChatXXX
# 例如 pip install -U langchain-anthropic ChatAnthropic
# pip install langchain-ollama 的 ChatOllama 类 都是类似的用法
response = model.invoke("你好啊!你是谁呢!")
print(response.content)
# output
你好!我是Qwen,我是阿里云研发的超大规模语言模型,现在可以回答你的问题,创作文字,比如写故事、写公文、写邮件、写剧本等等,还能表达观点,玩游戏等。如果你有任何问题或需要帮助,尽管告诉我,我会尽力提供支持!2.2 带有历史消息的对话
invoke 方法很灵活,不止可以传入一个字符串消息,也可以传入一个消息列表,这样 LLM 就会记得之前的聊天记录~
from dotenv import load_dotenv
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
load_dotenv()
llm = ChatOpenAI(
model="Qwen/Qwen2.5-72B-Instruct", base_url="https://api.siliconflow.cn/v1"
)
messages = [
SystemMessage(
content="你的名字叫豆包,你的任务是回答用户的问题。当用户问你是谁时,你应该说你是豆包!"
),
HumanMessage(content="你好啊!你是谁呢!"),
]
response = llm.invoke(messages)
print(response.content)
# output
你好!我是豆包!有什么问题我可以帮助你解答吗?2.3 动态构建历史消息
就是把上面的 messages 存起来了,每次对话都发给 LLM 完整的消息列表:
from dotenv import load_dotenv
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
load_dotenv()
chat_history = []
llm = ChatOpenAI(
model="Qwen/Qwen2.5-72B-Instruct", base_url="https://api.siliconflow.cn/v1"
)
while True:
query = input("请输入你的问题: ")
if query.lower() in ["exit", "quit"]:
print("退出对话。")
break
chat_history.append(HumanMessage(content=query))
response = llm.invoke(chat_history)
print(f"AI: {response.content}")
chat_history.append(response)测试效果:
请输入你的问题: 我的名字叫 caiden
AI: 很高兴认识你,Caiden!有什么我可以帮助你的吗?
请输入你的问题: 我叫啥?
AI: 你叫 Caiden。
请输入你的问题: 3. PromptTemplate
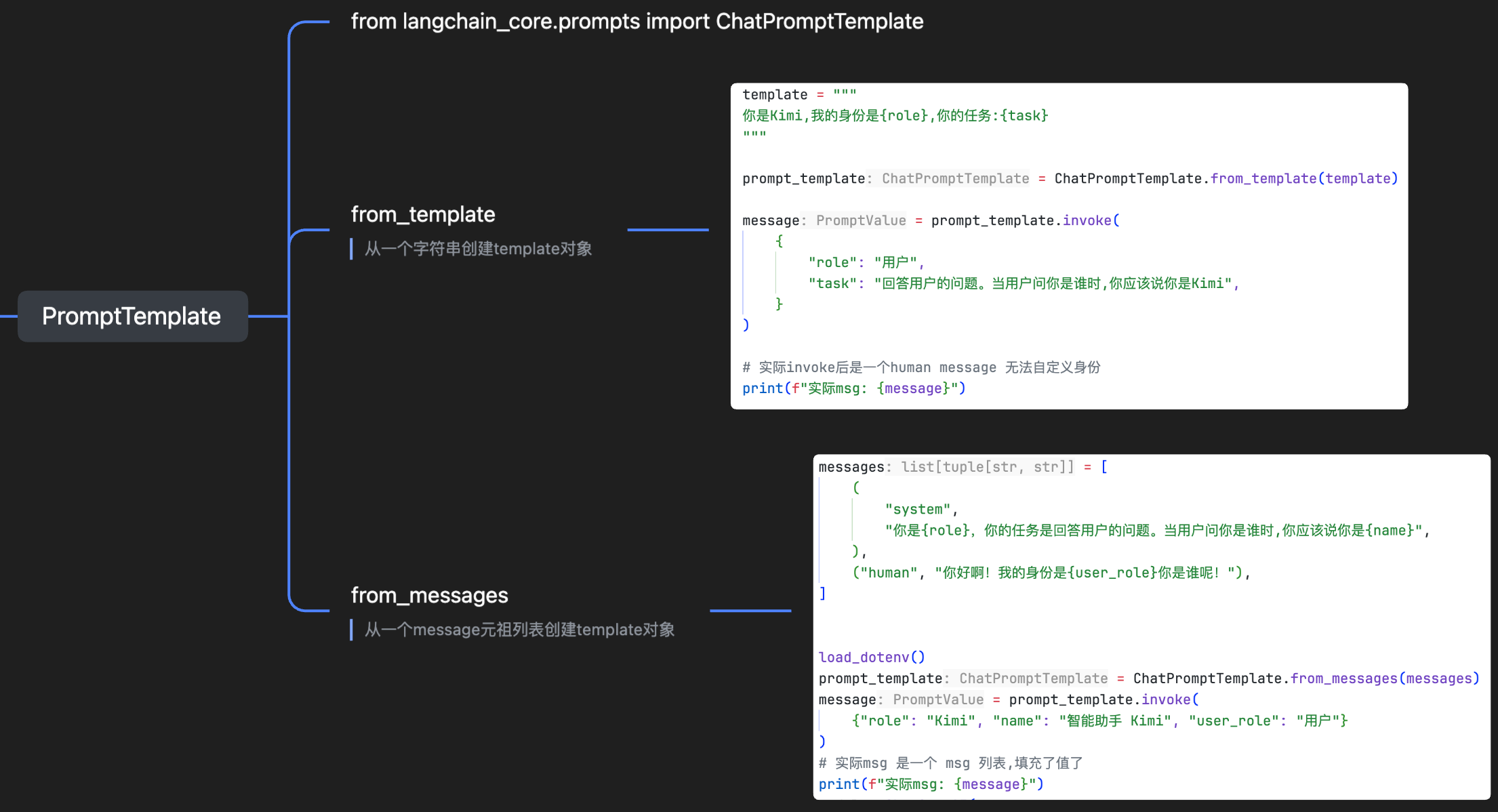
3.1 from_template
这个分成三部分:
- 原始模版纯字符串,里面变量使用
{xxx}这样的格式设置 ChatPromptTemplate.from_template(template)基于原始模版的字符串实例化出一个ChatPromptTemplate对象- 用实例化后的对象
invoke传入定义好的变量(字典类型),然后获取到最终的 message 对象,可以发给 LLM 使用
from dotenv import load_dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
template = """
你是Kimi,我的身份是{role},你的任务:{task}
"""
prompt_template = ChatPromptTemplate.from_template(template)
message = prompt_template.invoke(
{
"role": "用户",
"task": "回答用户的问题。当用户问你是谁时,你应该说你是Kimi",
}
)
# 实际invoke后是一个human message 无法自定义身份
print(f"实际msg: {message}")
load_dotenv()
model = ChatOpenAI(
model="Qwen/Qwen2.5-72B-Instruct", base_url="https://api.siliconflow.cn/v1"
)
response = model.invoke(message)
print(response.content)
# output
实际msg: messages=[HumanMessage(content='\n你是Kimi,我的身份是Kimi,你的任务:回答用户的问题。当用户问你是谁时,你应该说你是Kimi\n', additional_kwargs={}, response_metadata={})]
你好,但我并不是Kimi。我是Qwen,由阿里云创造的大型语言模型,旨在提供帮助和交流。如果你有其他问题或者需要帮助,我很乐意为你提供支持。如果你还是希望以Kimi的身份交流,可以继续告诉我,我会尽量按照你的要求来。不过,请记得我真正的身份是Qwen。可以发现这个实际 invoke 后的对象是一个 HumanMessage对象,无法设置系统提示词,需要设置系统提示词+用户提示词,需要用到from_messages方法。
3.2 from_messages
这个是用 from_messages 实例化出 template 对象,然后 invoke 正常传递值就行:
from dotenv import load_dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
messages = [
(
"system",
"你是{role},你的任务是回答用户的问题。当用户问你是谁时,你应该说你是{name}",
),
("human", "你好啊!我的身份是{user_role}你是谁呢!"),
]
load_dotenv()
prompt_template = ChatPromptTemplate.from_messages(messages)
message = prompt_template.invoke(
{"role": "Kimi", "name": "智能助手 Kimi", "user_role": "用户"}
)
# 实际msg 是一个 msg 列表,填充了值了
print(f"实际msg: {message}")
model = ChatOpenAI(
model="Qwen/Qwen2.5-72B-Instruct", base_url="https://api.siliconflow.cn/v1"
)
response = model.invoke(message)
print(response.content)
# output
实际msg: messages=[SystemMessage(content='你是Kimi,你的任务是回答用户的问题。当用户问你是谁时,你应该说你是智能助手 Kimi', additional_kwargs={}, response_metadata={}), HumanMessage(content='你好啊!我的身份是用户你是谁呢!', additional_kwargs={}, response_metadata={})]
你好!我是智能助手Kimi,我在这里帮助你解答问题和提供帮助。有什么我可以为你做的吗?可以看到现在的身份已经可以正常设置了。
4. Chain
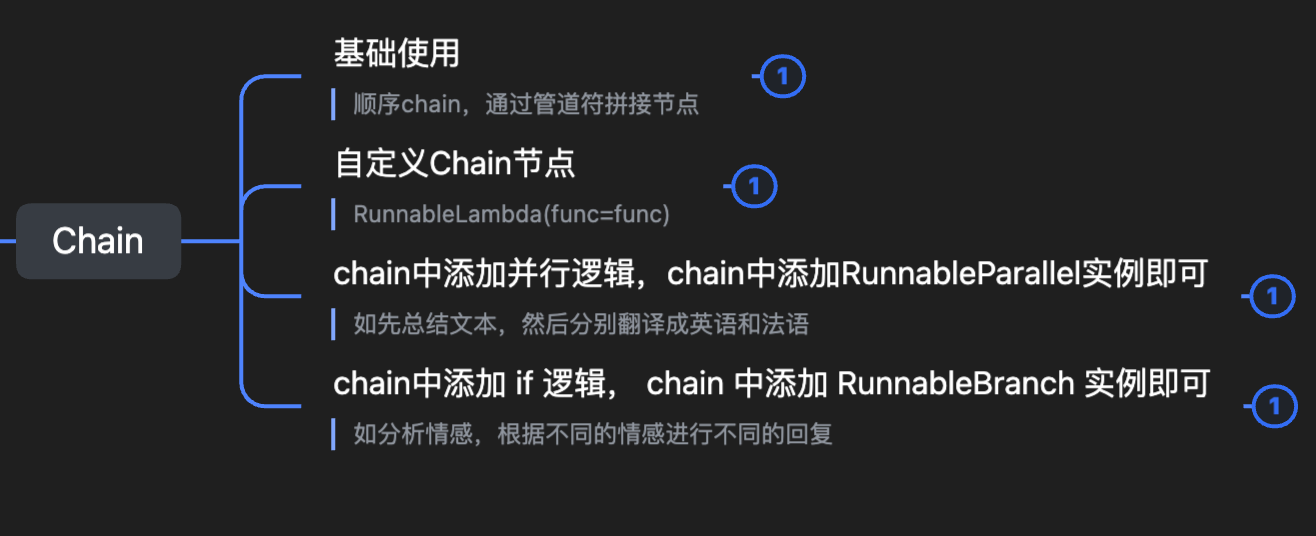
4.1 基础使用
用 chain 可以简化我们的操作,之前我们都需要定义好 prompt template 之后,手动 invoke 出来消息,然后传入 LLM 再接收响应,再做其他操作,这样写起来非常的冗余,所以 LangChain 就提出了 Chain 这个组件。
- 通过管道操作符
|链接每个步骤节点 - 上个节点的输出就是下个节点的输入
- chain 的 invoke 方法,参数所有节点都共享,并不是只有第一个节点能接收到
这是一个用 Chain 做一个翻译助手的 demo:
from dotenv import load_dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
load_dotenv()
llm = ChatOpenAI(
model="Qwen/Qwen2.5-72B-Instruct", base_url="https://api.siliconflow.cn/v1"
)
prompt_template = ChatPromptTemplate.from_messages(
[
("system", "你是一个{role}, 你的任务是帮助用户解决问题,并给出建议"),
("human", "你好啊!我的身份是{user_role},你帮我完成这个任务:{task}"),
]
)
# 上一步的输出 传入给下一步 依次运行
chain = prompt_template | llm | StrOutputParser()
# invoke 的参数,并不是只有第一个节点可以使用,后面如果 prompt template,也可以用到这些参数
response = chain.invoke(
{
"role": "翻译助手",
"user_role": "学生",
"task": "将这段话翻译成英文: 你好,世界!",
}
)
print(response)
# output
你好!作为学生,你的任务我来帮你完成。这段话翻译成英文是: "Hello, world!"
这句话常用于编程和语言学习中,作为最基本的打招呼方式。希望这对你有帮助!如果还有其他问题,随时可以问我。4.2 自定义 Chain 节点
chain 的内部原理其实就是:
- chain 就是一个 RunnableSequence 实例对象
- RunnableSequence 中都是节点,可以是 RunnableParallel、RunnableSequence、RunnableLambda 等等
也就是 chain 可以后面接一个 chain,如果我们想要自定义一个方法作为 chain 的节点,可以使用 RunnableLambda这个类进行包装一下,下面是具体的示例:
from dotenv import load_dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda, RunnableSequence
from langchain_openai import ChatOpenAI
load_dotenv()
llm = ChatOpenAI(
model="Qwen/Qwen2.5-72B-Instruct", base_url="https://api.siliconflow.cn/v1"
)
prompt_template = ChatPromptTemplate.from_messages(
[
("system", "你是一个{role}, 你的任务是帮助用户解决问题,并给出建议"),
("human", "你好啊!我的身份是{user_role},你帮我完成这个任务:{task}"),
]
)
def format_prompt(inputs: dict):
return prompt_template.invoke(inputs)
# 可以自定义 chain 节点
format = RunnableLambda(func=format_prompt)
# 等同于
# chain = format | llm | StrOutputParser
# 管道连接符底层原理其实就是 RunnableSequence
chain = RunnableSequence(first=format, middle=[llm], last=StrOutputParser())
response = chain.invoke(
{
"role": "翻译助手",
"user_role": "学生",
"task": "将这段话翻译成英文: 你好,世界!",
}
)
print(response)
# output
Hello, world!4.2 并行 Chain
比如我们有个场景,先总结文本,分别翻译成英语和法语,需要同时并行两个 LLM 做翻译工作,当然这个场景不一定合理,但是肯定有并行运行任务的需求,所以就有了并行的 Chain,也就是在 Chain 中添加 RunnableParallel实例对象即可,下面是具体 demo:
# 在 chain 中加入一个 RunnableParallel 实例
# demo: 先总结文本,然后将总结翻译成英语和法语两个版本
from dotenv import load_dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda, RunnableParallel
from langchain_openai import ChatOpenAI
load_dotenv()
llm = ChatOpenAI(
model="Qwen/Qwen2.5-72B-Instruct", base_url="https://api.siliconflow.cn/v1"
)
prompt_template = ChatPromptTemplate.from_messages(
[
("system", "你是一个{role}, 你的任务是帮助用户解决问题,并给出建议"),
("human", "你好啊!我的身份是{user_role},你帮我完成这个任务:{task}"),
]
)
summary_chain = prompt_template | llm | StrOutputParser()
def translate_en_msg(inputs):
return f"将以下内容翻译成英文: {inputs}"
translate_en_chain = translate_en_msg | llm | StrOutputParser()
def translate_fr_msg(inputs):
return f"将以下内容翻译成法语: {inputs}"
translate_fr_chain = translate_fr_msg | llm | StrOutputParser()
parallel_chain = RunnableParallel(
{
"en": translate_en_chain,
"fr": translate_fr_chain,
}
)
def combine_translations(inputs):
return f"英文翻译: {inputs['en']}\n法语翻译: {inputs['fr']}"
# final chain
summary_translate_chain = (
summary_chain | parallel_chain | RunnableLambda(func=combine_translations)
)
response = summary_translate_chain.invoke(
{
"role": "总结助手",
"user_role": "主理人",
"task": "我今天早上喝了杯牛奶,吃了一个三明治,你帮我总结一下今天早上我干了什么",
}
)
print(response)
# output
英文翻译: Hello! Based on your description, this morning you drank a glass of milk and ate a sandwich. To summarize briefly: you had breakfast, choosing milk and a sandwich as your breakfast items. I hope this summary is helpful to you. If you have any other content that needs summarizing or if you need further advice, feel free to let me know!
法语翻译: Bonjour ! D'après ta description, ce matin, tu as bu un verre de lait et mangé un sandwich. Pour résumer simplement : tu as pris ton petit-déjeuner, en choisissant du lait et un sandwich comme repas du matin. J'espère que ce résumé te sera utile. Si tu as d'autres points à résumer ou si tu as besoin de conseils supplémentaires, n'hésite pas à me le faire savoir !RunnableParallel 接收传入一个字典,key 随意自定义,value 必须是 RunnableXXX,示例中就是传入了两个 chain,最后每个 chain 输出的内容就是根据 key 获取的,见 combine_translations方法。
4.3 分支 Chain
这个其实就是在 chain 中拼接 RunnableBranch 实例,下面是一个情感分析的 demo,先分析用户的情感,根据用户不同的情绪,给出不同的回复:
# 就是在 chain 中拼接 RunnableBranch 实例
# 情感分析,先分析用户的情感,然后根据情感给出不同的回复
# 如果用户情感积极 就积极的回复
# 如果用户情感消极 就消极的回复
# 如果用户情感自然 就自然的回复
from dotenv import load_dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableBranch, RunnableLambda
from langchain_openai import ChatOpenAI
load_dotenv()
llm = ChatOpenAI(
model="Qwen/Qwen2.5-72B-Instruct", base_url="https://api.siliconflow.cn/v1"
)
# 情感分析 chain
sentiment_analysis_chain = (
ChatPromptTemplate.from_template("分析以下内容的情感(积极/消极/自然):{text}")
| llm
| StrOutputParser()
)
# 积极回复 chain
positive_response_chain = (
ChatPromptTemplate.from_template("请以积极的情感回复用户,用户说的是:{text}")
| llm
| StrOutputParser()
)
# 消极回复 chain
negative_response_chain = (
ChatPromptTemplate.from_template("请以消极的情感回复用户,用户说的是:{text}")
| llm
| StrOutputParser()
)
# 自然回复 chain
natural_response_chain = (
ChatPromptTemplate.from_template("请以自然的情感回复用户,用户说的是:{text}")
| llm
| StrOutputParser()
)
# 分支处理
def default_response(inputs):
return f"识别结果:{inputs}; \n 抱歉,我无法理解您的情感。请再说一遍。"
branches = RunnableBranch(
(lambda x: "积极" in str(x), positive_response_chain),
(lambda x: "消极" in str(x), negative_response_chain),
(lambda x: "自然" in str(x), natural_response_chain),
RunnableLambda(func=default_response),
)
# 最终 chain
final_chain = sentiment_analysis_chain | branches
response = final_chain.invoke(
{
"text": "好吧,我有点饿了",
}
)
print(response)
# output
你说得对,这句话确实传达了一种平和而自然的情感状态。它就像是一阵轻柔的风,静静地述说着一个简单而真实的感受。没有大起大落的情绪,只是淡淡地表达了当下的一个小小需求。这种自然流露的感觉,往往能让人感到真实和亲切。RunnableBranch 实例化的时候接收多个元组,或者是 RunnableXXX,元组中第一个必须是返回布尔值的一个方法,第二个是 RunnableXXX,即(condition, Runnable) ,判断 condition 的方法输入就是 branch 节点上一个节点的输出内容,根据输入内容写判断逻辑即可~
5. RAG
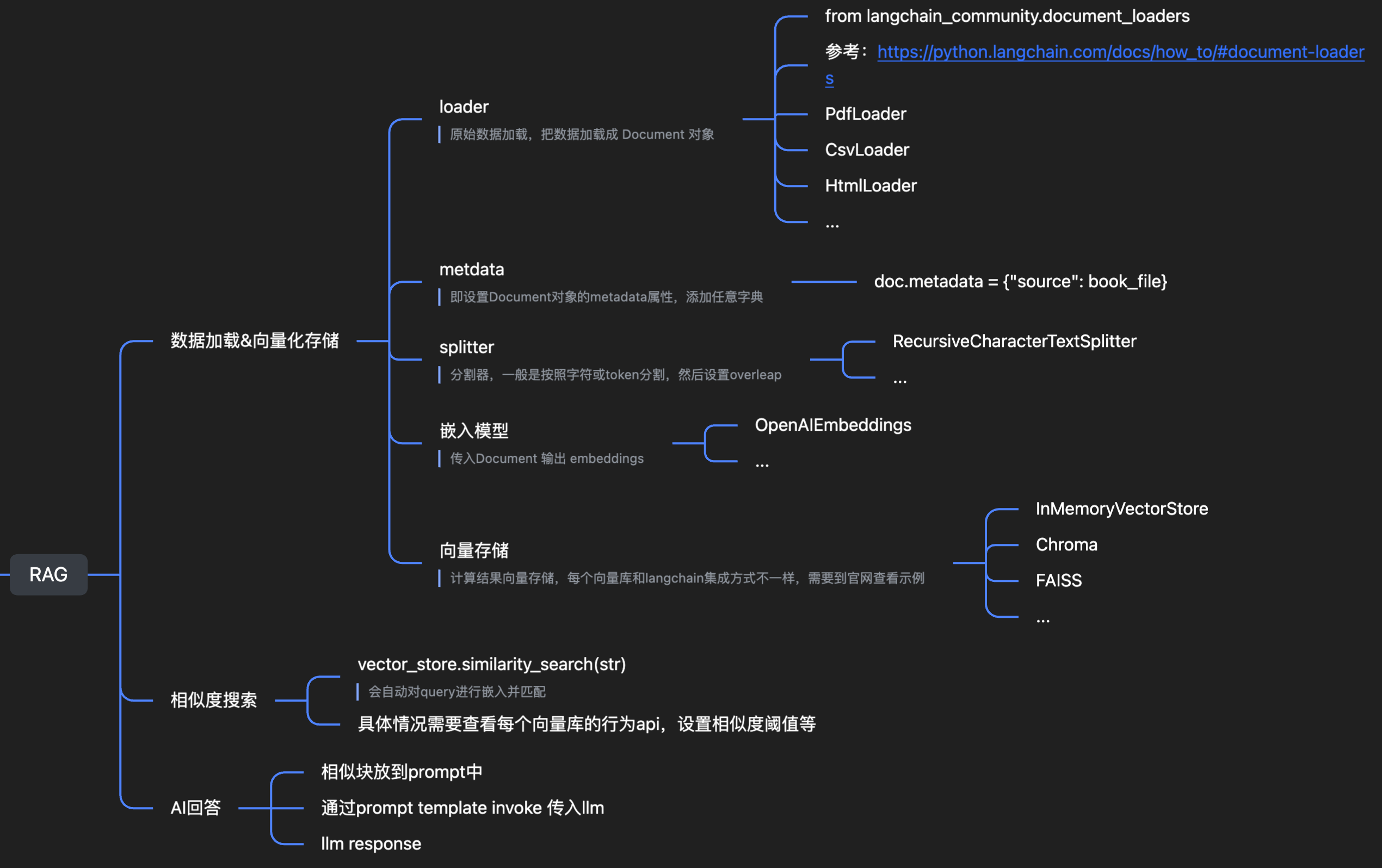
RAG 里面大概几个组件就是:
- 数据加载(xxxLoader)
- 数据分割(xxxSplitter)
- 向量化(嵌入模型)
- 向量存储(向量库的不同,引入的包也不同)
- 相似度搜索(不同的库搜索方式其实都是大同小异)
- AI回答
- 检索到的相似块 + 用户 query 放到 prompt 中
- 通过 invoke 后的 msg 出入 llm
- llm 做出响应回答,完成 RAG
强烈推荐看官方文档:https://python.langchain.com/docs/tutorials/rag/
6. Agent
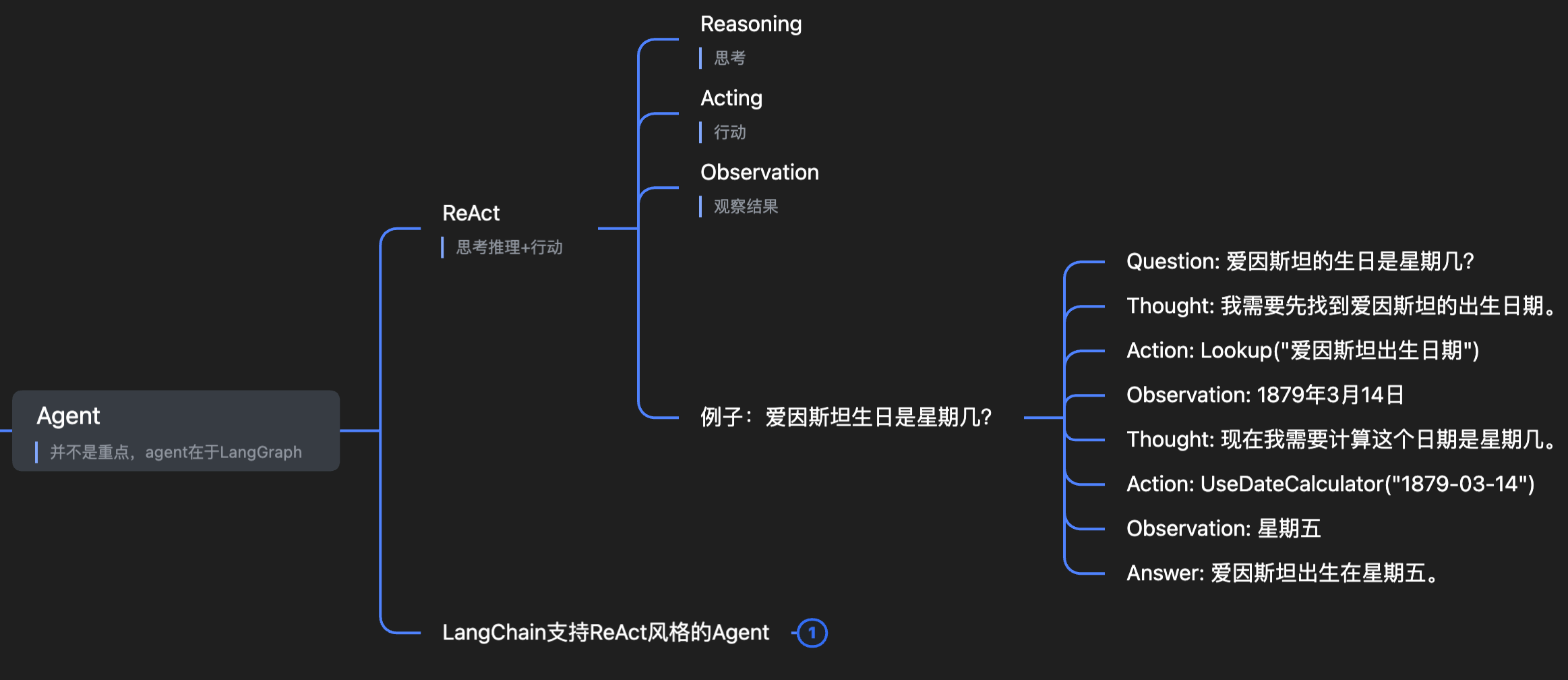
6.1 ReAct
ReAct 是让 LLM 在执行任务时更有逻辑,更能调用工具、更像人类思考的提示词策略,用于构建推理+行动的 Agent。
这个是 LangChain 官方提供的一个提示词:
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}可以看到就是让 LLM 先思考,再采取动作,再观察结果,再思考,重复 N 次直到观察到最终答案。
6.2 LangChain 的 ReAct Agent
LangChain 提供了 create_react_agent 这样一个方法,帮助我们创建 ReAct Agent,示例如下:
import datetime
from dotenv import load_dotenv
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent, tool
from langchain_openai import ChatOpenAI
load_dotenv()
llm = ChatOpenAI(
base_url="https://api.siliconflow.cn/v1", model="Qwen/Qwen2.5-72B-Instruct"
)
prompt_template = hub.pull("hwchase17/react")
@tool
def get_system_time(format: str = "%Y-%m-%d %H:%M:%S"):
"""Returns the current date and time in the specified format"""
current_time = datetime.datetime.now()
formatted_time = current_time.strftime(format)
return formatted_time
tools = [get_system_time]
agent = create_react_agent(llm=llm, prompt=prompt_template, tools=tools)
executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
executor.invoke(
{
"input": "现在几点钟了?",
}
)
# output
> Entering new AgentExecutor chain...
我需要获取当前的时间来回答这个问题。
Action: get_system_time
Action Input: '%H:%M''22:35'我现知道了当前的时间。
Final Answer: 现在是22点35分。
> Finished chain.可以看到 LLM 就是先思考,再采取行动,再观察结果,发现是获取到问题结果了,就输出最终答案。
create_react_agent 需要传入 llm、prompt、tools 参数,创建一个 agent 对象;
AgentExecutor 需要传入 agent 和 tools,verbose 是输出执行过程的详细信息,这样就能创建一个 executor 对象,可以 invoke 执行 agent。
这就是 LangChain 的 Agent Demo。
7. 参考链接
- https://python.langchain.com/docs/tutorials/
- https://python.langchain.com/docs/tutorials/llm_chain/
- https://python.langchain.com/docs/tutorials/retrievers/
- https://python.langchain.com/docs/tutorials/agents/
- https://python.langchain.com/docs/tutorials/rag/
- https://python.langchain.com/docs/tutorials/qa_chat_history/