大模型相关概念讲解:模型、大模型、大语言模型、大模型分类、Token、向量数据库、RAG、Ollama、Dify
1. 模型
1.1. 模型的概念及说明
在人工智能中,模型可以理解为一个“函数”或“算法”。它接收输入(例如文本、图像),经过内部的计算后,输出结果(例如回答、描述)。
用一个简单的数学类比来看
-
模型类似于一个数学函数,例如 y = f(x) = ax+b,其中:
-
x 是输入。
-
y 是输出。
-
a 和 b 是这个函数中的“参数”,模型要通过训练找到这些参数。
-
1.2. 模型的训练
训练模型的过程就是通过大量的输入-输出对(x, y),让模型不断调整内部的参数,让实际输出尽量接近目标输出。
过程如下:
- 机器学习通过一个优化算法:反复计算函数 f(x) 的结果(比较真实值和预测值之间的差异,称为“误差”)。
- 调整参数(比如 a 和 b)直到误差最小。
- 最终,这些经过优化的参数会被保存为一个“模型文件”(通常后缀如 .pt/.h5 等)。
示例:
- 如果给一个模型输入很多线性数据对(如:(x=1, y=3) (x=2, y=5) …),
- 它会调整参数 a=2,b=1,最终数学表达式 f(x)=2x+1 成为最佳拟合函数(或称为模型)。
1.3. 推理(Inference)
模型训练好后,被用来实际解决问题的阶段叫做推理。即:
- 加载模型文件,把训练好的参数(如 a 和 b)加载进系统。
- 用户输入(x),通过计算 f(x)=ax+b,得到结果(输出 y)。
2. 大模型
大模型(Large Model),直白来说,指的是参数规模非常大的模型。它拥有数亿甚至数千亿个参数(如 DeepSeek R1 满血 671B 参数,就是 6710 亿)。参数越多,模型的学习能力和表达能力就越强,能解决的任务也越复杂。
举例:
- 小模型:像一台基础的计算器,可以完成简单的任务(如加减法)。
- 大模型:像一台超级计算机或者百科全书,能够处理复杂的任务(如图像识别、自然语言理解和生成、多模态任务等)。
3. 大语言模型(LLM)
大语言模型(LLM,Large Language Model)是大模型的一个分支,专门用来处理文本相关任务,比如阅读、理解和生成文章。
核心能力:理解和生成自然语言。
简单来说:给它一段文字,它可以帮你续写文章、翻译语言、回答问题、生成代码、写诗等等
4. 大模型分类
4.1. 根据输入类型分类
- 文本模型: 处理文本数据,如大语言模型(LLM)。
- 图像模型: 处理图像数据,如图像识别、图像生成模型。
- 语音模型: 处理语音数据,如语音识别、语音合成模型。
- 多模态模型: 可以同时处理多种类型的数据,如文本、图像、语音等。
4.2. 根据应用领域分类
- 通用模型: 适用于多种任务,如ChatGPT。
- 行业模型: 针对特定行业进行优化,如金融、医疗等。
5. 大模型中的 Token
Token 是大模型处理文本的基本单位。
-
可以理解为:将一段文本拆分成一个个的小片段,每一个小片段就是一个 Token,具体取决于模型的分词策略
-
例如:
- “Hello world” 可能被拆分成 “Hello” 和 “world” 两个 Token。
- “你好世界” 可能被拆分成 “你好” 和 “世界” 两个 Token 。
-
Token 的重要性:
- 模型的输入输出都是以 Token 为单位
- 模型的处理能力(如一次能处理的最大文本长度)通常是以 Token 数量来衡量
- Token 数量也会影响模型的推理成本(费用)
6. 向量数据库
6.1. 向量数据库概念
向量数据库(Vector Database) 是一种专门设计用于存储、管理和高效查询向量(高维数据表示)的数据库系统。
简单来说,这里的“向量”可以理解为把复杂的东西(比如一段文字、一张图片、一个音频文件)用数学的方法转化成一串数字(可能是几百甚至几千维的数组)。这些数字“向量”能够非常方便地用来比较相似性。
6.2. 向量数据库 vs 传统数据库
- 传统数据库强调精确匹配(如查找主键、ID)。
- 向量数据库则专注于相似匹配(比如找出和当前输入“意思最接近”的内容)。
6.3. 使用场景
- 推荐系统: 根据用户行为推荐类似的物品。
- 智能检索: 输入一段语句,找到语义相似的资料。
- 配合 RAG: 提供海量外部知识。
7. RAG
RAG (Retrieval-Augmented Generation) 是一种增强大模型能力的策略。
- 核心思想:在生成答案之前,先从外部知识库中检索相关信息,然后将这些信息作为 Prompt 的一部分,一起输入给大模型。
- 简单理解:给大模型提供了一个“外脑”,让它在回答问题时,可以参考外部知识,从而生成更准确、更全面的答案。
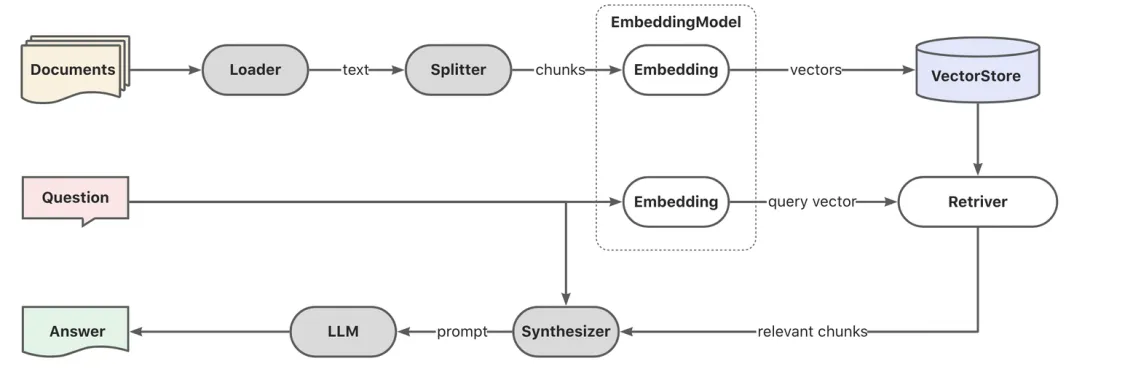
典型 RAG 流程
- 文档分块编码文档的向量表示(embeddings)。
- 用户输入提示词之后,对提示词也进行转换向量表示。
- 拿转换为向量的提示词去向量数据库中做向量相似性检索,返回搜索出来的关联文档块。
- 拿关联文档块作为上下文,加上提示词一块输入给大模型。
- 大模型推理回复。
8. 目前用到的工具
8.1. Ollama
Ollama 是一个开源工具,它的核心作用是让你非常轻松地在本地电脑上运行大型语言模型 (LLM)。
它本身并不是一个大模型,而是一个平台或者工具,帮你管理、部署和运行那些大型模型,比如 Llama 2、Mistral 等等。
部署简单:可以把Ollama想象成LLM的Docker。
多平台支持: Ollama 支持 macOS、Linux 和 Windows。
8.2. Dify
Dify 是一个基于 LLM (Large Language Model) 的应用开发平台,旨在降低开发者构建 AI 原生应用的门槛。
Dify 提供了一套完整的工具链,包括可视化 Prompt 编排、上下文增强、知识库管理、Agent 调度和统一的 API 接口等功能,帮助开发者快速构建各种 AI 应用,如聊天机器人、知识问答系统、AI 工作流等。
Dify 支持多种 LLM 模型,包括 OpenAI、Anthropic、Google 等,并提供了灵活的部署方案,包括云端部署和本地部署,满足不同场景下的需求。
Dify 的核心价值在于简化 AI 应用的开发流程。