本地虚拟环境搭建 Hadoop 集群,是集群搭建的过程记录
整体流程
基于 CentOS7.5、JDK1.8、Hadoop3.1.3 搭建
- 准备一台模板机,模板机需要配置好以下内容
- 网络、主机名配置
- epel-release 安装(Extra Packages for Enterprise Linux 是为“红帽系”的操作系统提供额外的软件包, 适用于 RHEL、CentOS 和 Scientific Linux。相当于是一个软件仓库,大多数 rpm 包在官方 repository 中是找不到的)
- 因为是本地测试环境,所以直接把防火墙关闭,并且关闭防火墙开机自启动,以后就不用单独开端口了
- 在 opt 下创建文件夹
- /opt/software:存放软件安装包
- /opt/module:软件安装目录,所有软件都安装到这里
- 卸载虚拟机自带 JDK
- 磁盘分区
- /boot: 1024 MB
- / : 45 G
- /swap: 4096 MB
- 然后通过这台模板机,克隆三台虚拟机做集群搭建
- 三台虚拟机分别修改ip、host,配置 hosts
- 一台虚拟机安装 JDK 和 Hadoop ,并配置环境变量
- 配置 ssh 免密登录
- 编写 xsync 分发脚本,将内容分发到另外两台机器
- 配置 Hadoop 相关配置文件
- 同步分发配置好的配置文件,初始化集群、启动 HDFS、启动 YARN
- 测试验证
- 存取文件
- MapReduce 计算任务提交
模板机准备
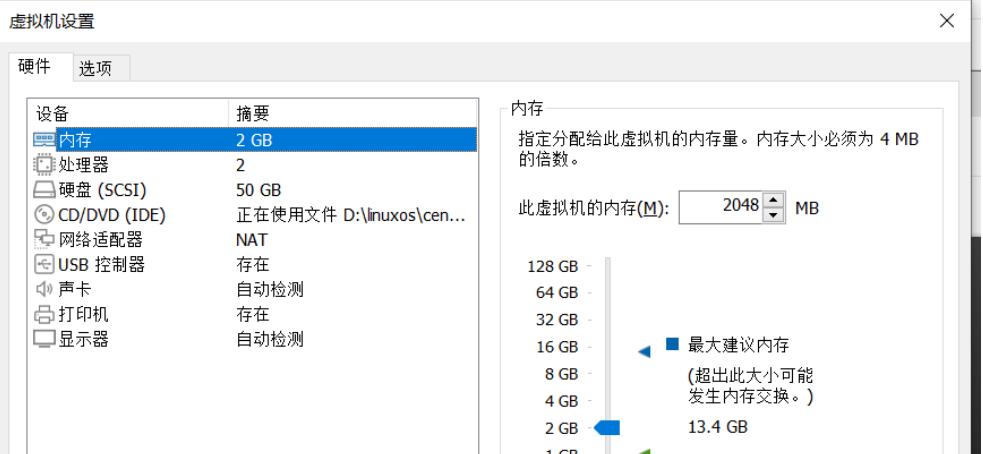
虚拟机配置
几个重要参数,需要根据自己实际情况来:
- 内存:我本地是 16G,所以 一台机器 2G 是没问题的,一共就是 2 * 3 = 6 G
- 处理器:我本地是 4 核 8 线程,所以一台机器 2 个 cpu,一共就是 2 * 3 = 6 C
- 硬盘:最低 50 G
- 操作系统:CentOS7.5
- 网络适配器:NAT
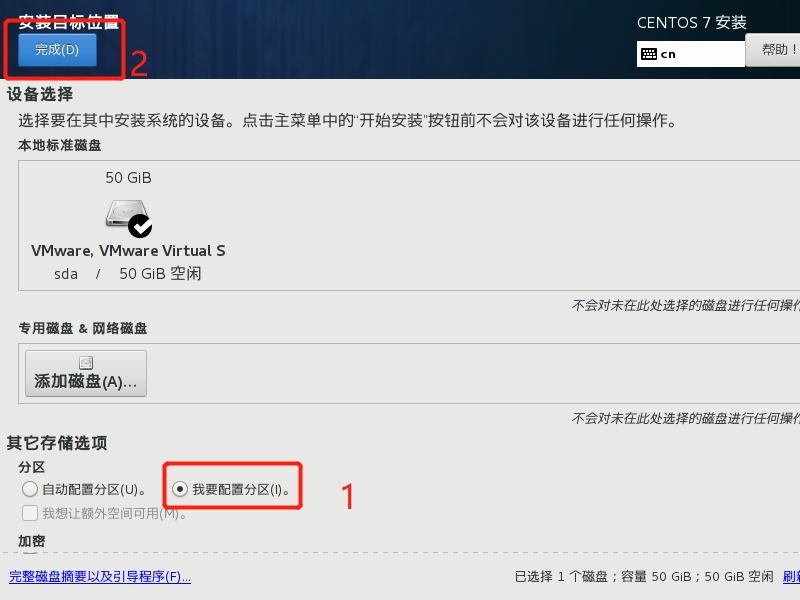
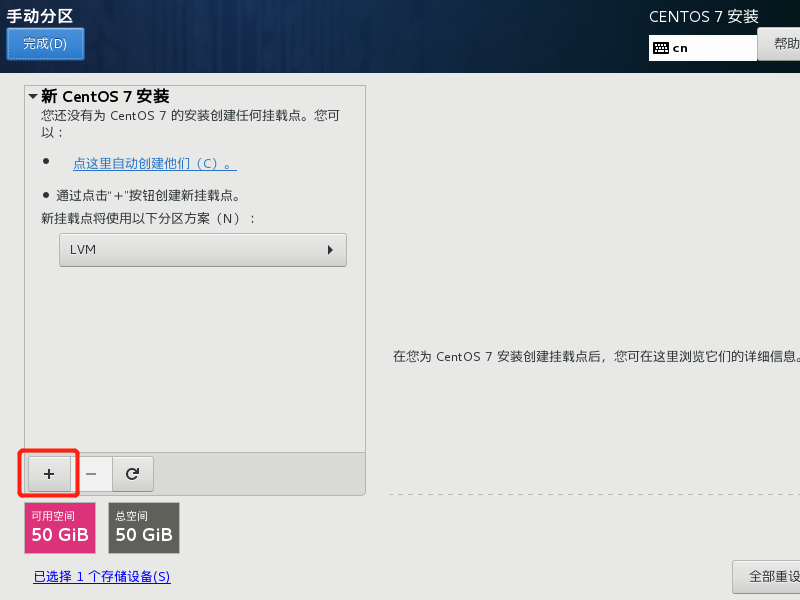
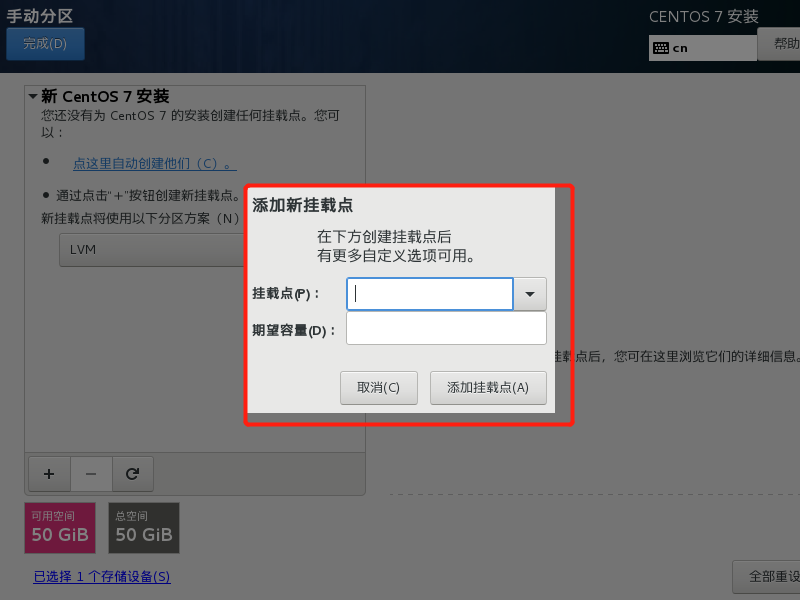
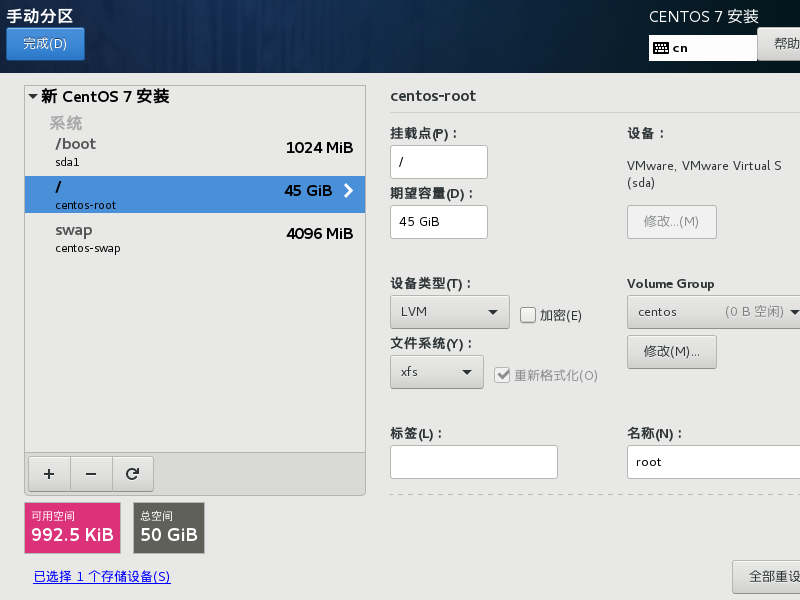
分区配置
- /boot: 1024 MB
- / : 45 G
- /swap: 4096 MB
具体如何设置如下图步骤
网络及主机名配置
IP 网段查看:虚拟机主界面 -> 编辑 -> 虚拟网络编辑器 -> 找到 NAT 模式的子网 IP
# 切换到root用户
su root
# 编辑网卡配置
vim /etc/sysconfig/network-scripts/ifcfg-ens33
# 改动
BOOTPROTO=static
# 新增
IPADDR=192.168.3.100
NETMASK=255.255.255.0
GATEWAY=192.168.3.2
DNS1=114.114.114.114
# 重启网络
service network restart
# 验证
ping baidu.com
# 配置主机名 hostname
vim /etc/hostname
# 重启 使用 hostname 命令查看是否生效
hostnameepel-release 安装
Extra Packages for Enterprise Linux 是为“红帽系”的操作系统提供额外的软件包, 适用于 RHEL、CentOS 和 Scientific Linux。相当于是一个软件仓库,大多数 rpm 包在官方 repository 中是找不到的
yum install -y epel-release关闭防火墙
# 关闭防火墙
[root@hadoop100 ~]# systemctl stop firewalld
# 关闭开机自启
[root@hadoop100 ~]# systemctl disable firewalld.service创建软件安装目录和安装包存放目录
# 软件包存放目录
[root@hadoop100 ~]# mkdir /opt/software
# 软件安装目录
[root@hadoop100 ~]# mkdir /opt/module卸载虚拟机自带 JDK
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps- rpm -qa:查询已安装的所有 rpm 软件包
- -i:忽略大小写
- xargs -n1:表示每次只传递一个参数
- rpm -e –nodeps:强制卸载软件
集群搭建
使用模板机克隆出三台机器做集群
克隆注意事项:
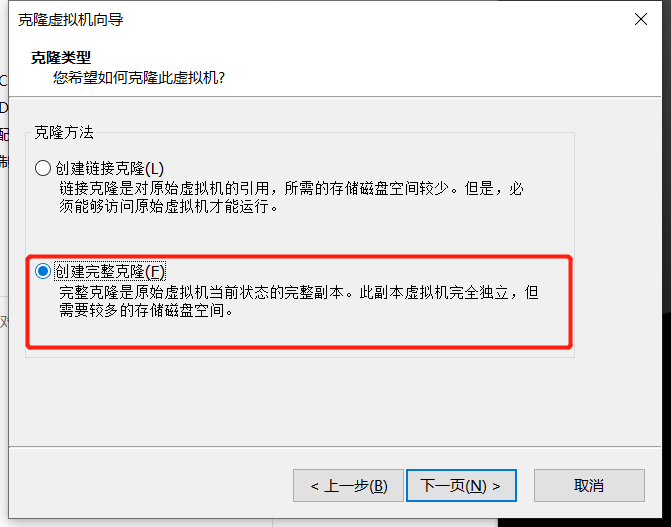
- 要选择完全克隆,而不是克隆一个链接
- 克隆之前一定要关闭虚拟机,这里就是关闭 hadoop100 这台机器
- 克隆时长和硬盘有关,机械硬盘大概三五分钟,固态的话就是二十多秒
具体步骤如下
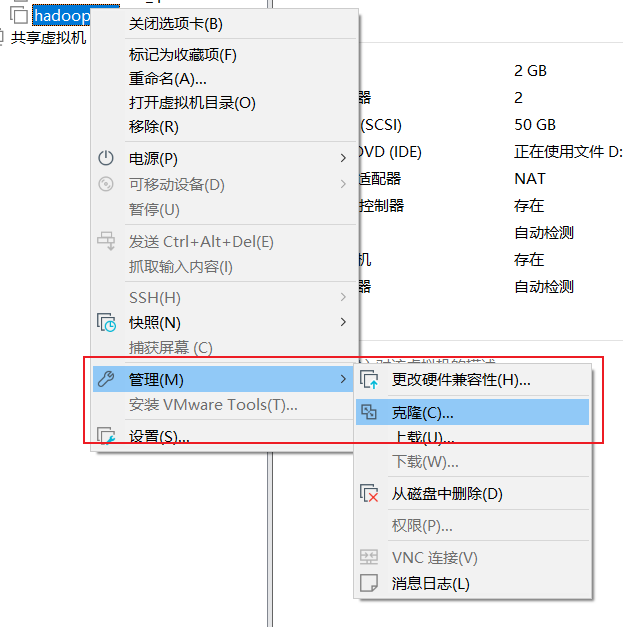
一直下一步,然后注意这里要选择创建完整克隆:
修改 ip 和 hostname
依次配置三台机器的 ip 和 hostname,步骤如下
只用修改 IPADDR 就行,分别改 102,103,104
# 切换到root用户
su root
# 编辑网卡配置
vim /etc/sysconfig/network-scripts/ifcfg-ens33
# 修改行
IPADDR=192.168.3.102
# 再修改 hostname
vim /etc/hostname
# 修改完毕后重启
reboot配置 hosts
vim /etc/hosts
# 在文件中加入以下内容
192.168.3.100 hadoop100
192.168.3.102 hadoop102
192.168.3.103 hadoop103
192.168.3.104 hadoop104
# 验证 三台机器可以互相ping一下
ping hadoop102
ping hadoop103
ping hadoop104这里建议在 windows 上也配置上面的 hosts,后面就不用 ip 访问了
JDK 安装
首先把 JDK 压缩包上传到 /opt/software 下
# 解压到/opt/module/
tar -zxvf jdk-8u131-linux-x64.tar.gz -C /opt/module/
# 配置环境变量
cd /etc/profile.d/
# 建一个自己的环境变量描述文件
vim my_env.sh
# 写入以下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_131
export PATH=$PATH:$JAVA_HOME/bin
# 重新加载环境变量
source /etc/profile
# 验证 输出版本信息完成安装
java -versionHadoop 安装
首先把 Hadoop 压缩包上传到 /opt/software 下
# 解压到/opt/module/
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
# 配置环境变量
vim /etc/profile.d/my_env.sh
# 添加以下内容
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 重新加载
source /etc/profile
# 验证 有内容输出代表完成安装
hadoop配置 ssh 免密登录
这个免密是这三台机器(hadoop102,hadoop103,hadoop104)之间互相 ssh 登录不用密码验证
三台机器一次执行以下内容
# 切换到 隐藏目录 .ssh 下,在这能方便的看到生成的密钥对 查看隐藏目录的方法 ll -a
cd /root/.ssh/
# 生成密钥对,输入命令 按三下回车
ssh-keygen -t rsa
# .pub 就是公钥 第一个就是私钥
[root@hadoop102 .ssh]# ll
总用量 12
-rw-------. 1 root root 1675 4月 18 17:24 id_rsa
-rw-r--r--. 1 root root 396 4月 18 17:24 id_rsa.pub
-rw-r--r--. 1 root root 185 4月 18 17:10 known_hosts
# 将公钥分发出去,免密登录配置完成
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104编写 xsync 分发脚本
# 进入到 /usr/bin 在这里写的可执行文件可以全局使用 而且任何用户都可用
cd /usr/bin
# 新建编辑脚本
vim xsync
# 写入以下内容
# 添加可执行权限
chmod +x xsync
# 把 xsync 分发到另外两台机器
xsync xsync
# 同步过程内容
[root@hadoop102 bin]# xsync xsync
==================== hadoop102 ====================
sending incremental file list
sent 44 bytes received 12 bytes 37.33 bytes/sec
total size is 740 speedup is 13.21
==================== hadoop103 ====================
sending incremental file list
xsync
sent 831 bytes received 35 bytes 577.33 bytes/sec
total size is 740 speedup is 0.85
==================== hadoop104 ====================
sending incremental file list
xsync
sent 831 bytes received 35 bytes 577.33 bytes/sec
total size is 740 speedup is 0.85xsync 脚本内容
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done脚本使用,脚本后面可以跟文件/目录,然后三台机器都会把这个文件(目录)同步到相同的内容
# 进入 opt 创建一个 test.txt
cd /opt
vim test.txt
# 随便写入点内容,然后同步
xsync test.txt
# 进入到其他机器上,可以看到 opt 下已经有了这个 txt 文件了
[root@hadoop103 ~]# cd /opt/
[root@hadoop103 opt]# ll
总用量 4
drwxr-xr-x. 2 root root 6 4月 18 16:19 module
drwxr-xr-x. 2 root root 6 9月 7 2017 rh
drwxr-xr-x. 2 root root 6 4月 18 16:19 software
-rw-r--r--. 1 root root 6 4月 18 20:18 test.txt
[root@hadoop103 opt]# cat test.txt
hello分发已安装的 JDK 和 Hadoop
# 直接同步 opt 目录
xsync /opt/
# 再同步环境变量
xsync /etc/profile.d/my_env.sh
# 去另外两台机器上,重新加载环境变量
source /etc/profile
# 验证
java -version
hadoop集群部署规划
注意点:
- NameNode 和 SecondaryNameNode 不要安装在同一台服务器,不然一个挂全挂了,起不到 2nn 的作用
- ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在同一台机器上。
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
配置 Hadoop 相关配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
-
核心配置文件 core-site.xml
# 进入配置文件目录,编写配置文件 cd /opt/module/hadoop-3.1.3/etc/hadoop vim core-site.xml配置文件内容,主要是指定 NameNode 的地址,也就是规划好的 hadoop102,还有就是指定存储目录,因为默认目录是存储在 /tmp 下的,/tmp 只是个临时目录
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> </configuration> -
HDFS 配置文件 hdfs-site.xml
vim hdfs-site.xml配置文件内容:配置可视化 web 地址,通过这个可以直接在 web 端查看集群存储情况
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> </configuration> -
YARN 配置文件 yarn-site.xml
vim yarn-site.xml配置文件内容:
<?xml version="1.0"?> <configuration> <!-- Site specific YARN configuration properties --> <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration> -
MapReduce 配置文件 mapred-site.xml
vim mapred-site.xml配置文件内容,这里配置 MapReduce 运行内存,为非必要项,但是在跑 MapReduce 程序时候可能会出现内存不足的情况,所以这里加了配置
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 配置 MapReduce 运行内存 --> <property> <name>mapreduce.map.memory.mb</name> <value>4096</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>4096</value> </property> </configuration> -
因为我使用的是 root 用户,所以还要额外配置一个配置文件
$HADOOP_HOME/etc/hadoop/hadoop-env.sh,在文件末尾添加以下内容export HDFS_NAMENODE_USER="root" export HDFS_DATANODE_USER="root" export HDFS_SECONDARYNAMENODE_USER="root" export YARN_RESOURCEMANAGER_USER="root" export YARN_NODEMANAGER_USER="root"如果不配置的话,启动集群的时候就会报错:
but there is no HDFS_NAMENODE_USER defined. Aborting operation. -
「重要」配置 workers
不配置这个,没法群起集群,不然 hadoop 都不知道有几台机器能用
cd /opt/module/hadoop-3.1.3/etc/hadoop vim workers # 把localhost 删掉,添加以下内容,注意,这个里面不允许有空格 空行这些 hadoop102 hadoop103 hadoop104
分发/同步 配置文件
# 进入 hadoop 目录,同步
cd /opt/module/hadoop-3.1.3
xsync etc/初始化集群
注意:只有集群是第一次启动才需要此操作,并且要在 hadoop102 上格式化 NameNode
格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化
hdfs namenode -format启动 HDFS 及 YARN
在 hadoop102 上启动集群
cd /opt/module/hadoop-3.1.3/sbin
start-dfs.sh在配置了 ResourceManager 的机器上(hadoop103) 上启动 YARN
cd /opt/module/hadoop-3.1.3/sbin
start-yarn.sh验证及测试
通过查看后台进程验证 HDFS 及 YARN 是否成功启动
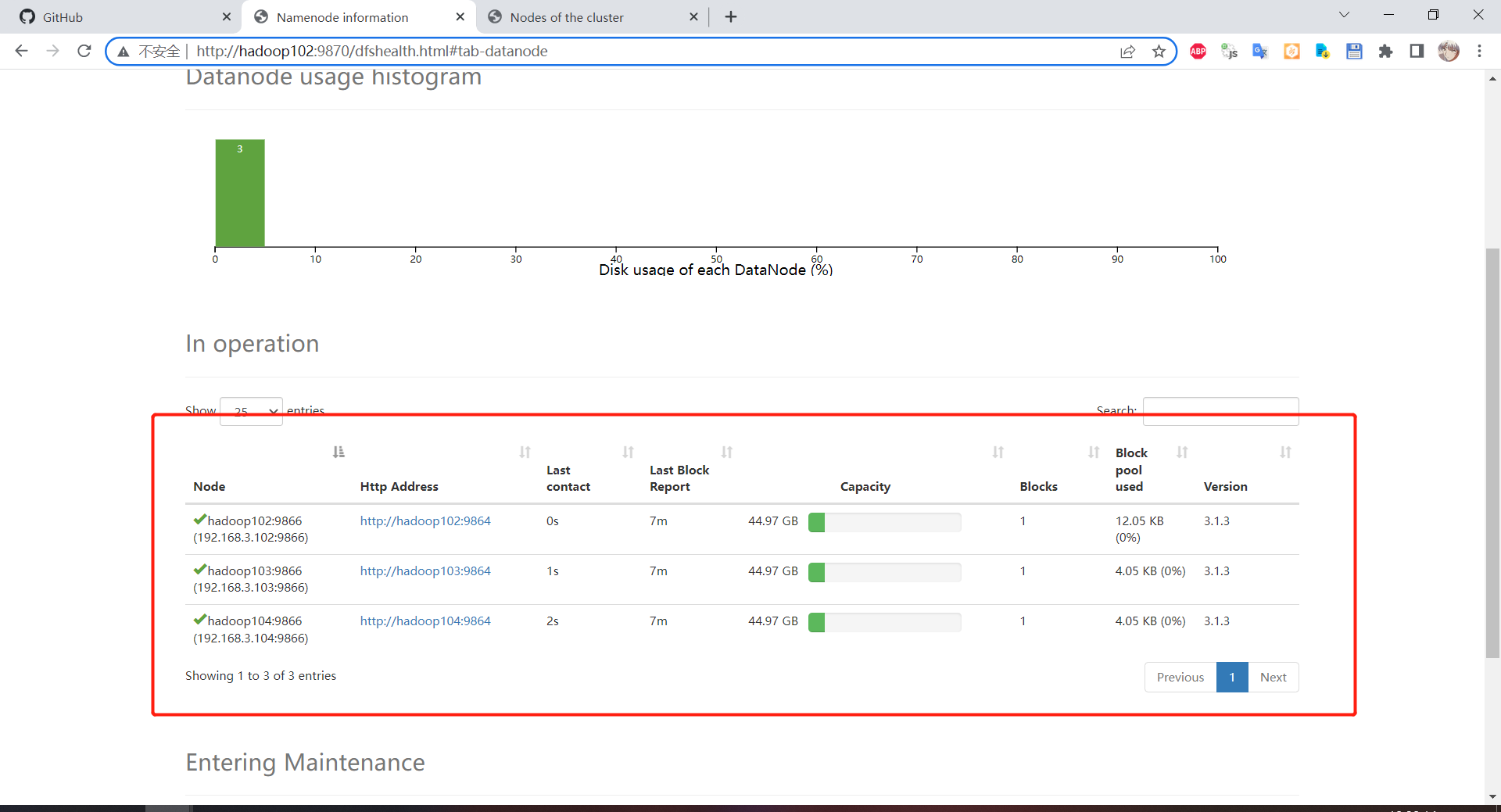
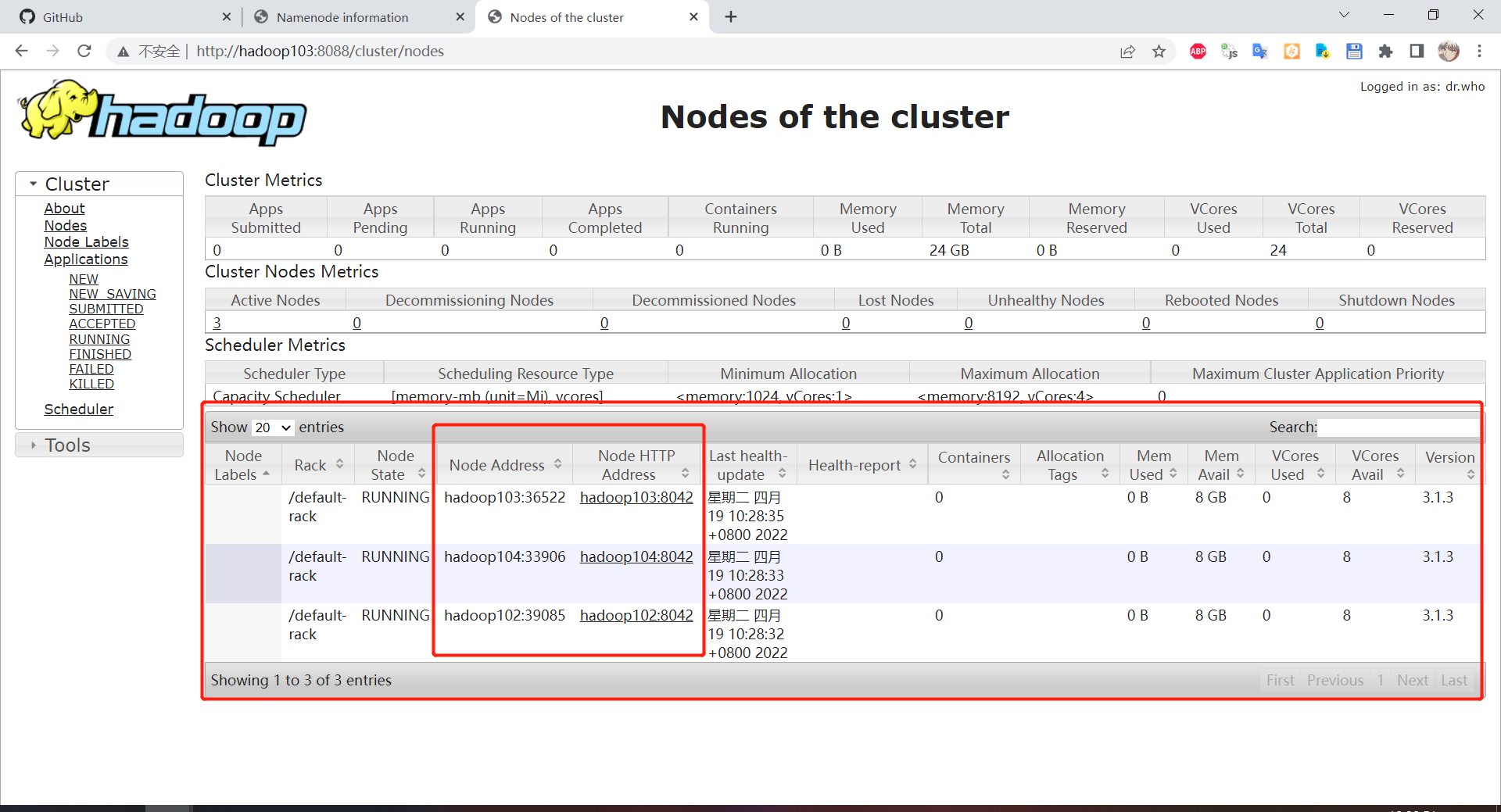
可以看到确实是按照部署规划完成部署,hadoop102 是 nn,hadoop103 是 rm,hadoop104 是 2nn
# 在三台机器上分别输入 jps 查看
# hadoop102
[root@hadoop102 sbin]# jps
15040 DataNode
14840 NameNode
15464 NodeManager
15579 Jps
# hadoop103
[root@hadoop103 sbin]# jps
13926 NodeManager
14374 Jps
13741 ResourceManager
13423 DataNode
# hadoop104
[root@hadoop104 ~]# jps
3395 NodeManager
3157 DataNode
3541 Jps
3241 SecondaryNameNode去 web 界面查看
-
到 HDFS 上查看集群节点情况:http://hadoop102:9870/dfshealth.html#tab-datanode
-
到 YARN 上查看集群节点情况:http://hadoop103:8088/cluster/nodes
上传文件到 HDFS 测试
-
在 HDFS 根目录下建一个 wcinput 目录
语法:
hadoop fs -mkdir [path]hadoop fs -mkdir /wcinput -
把本地文件上传到 HDFS 上
语法:
hadoop fs -put [source] [dest]# 编辑一个 word.txt 文件做分词使用 vim word.txt # 写入测试内容,随意 houge houge cheng ceshi ceshi ceshi # 上传到 HDFS 根目录下的 wcinput 文件夹中 hadoop fs -put word.txt /wcinput -
再往 HDFS 的根目录下传一个大一点的文件
cd /opt/software hadoop fs -put jdk-8u131-linux-x64.tar.gz / -
到 web 端查看是否上传成功
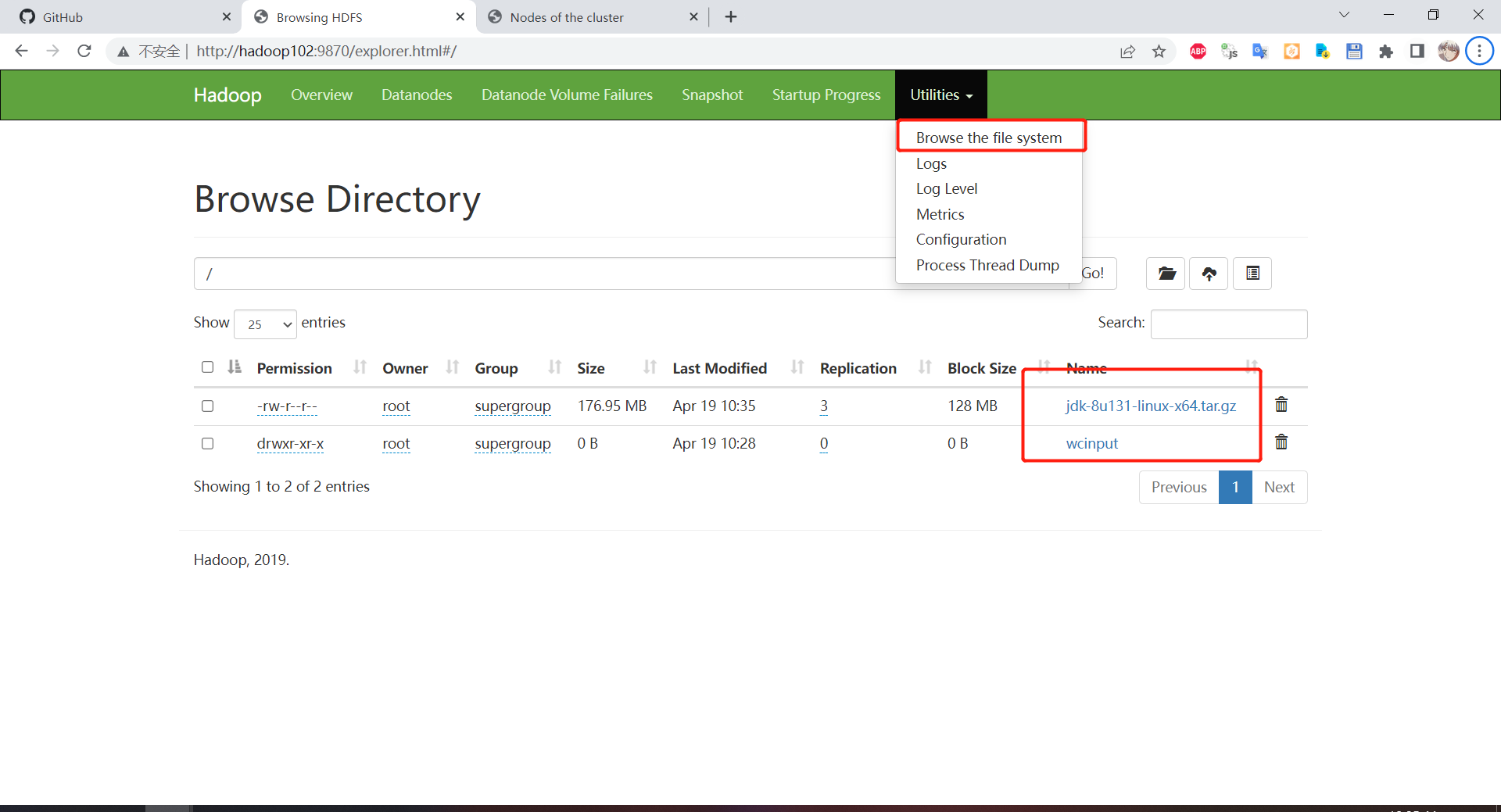
查看 word.txt
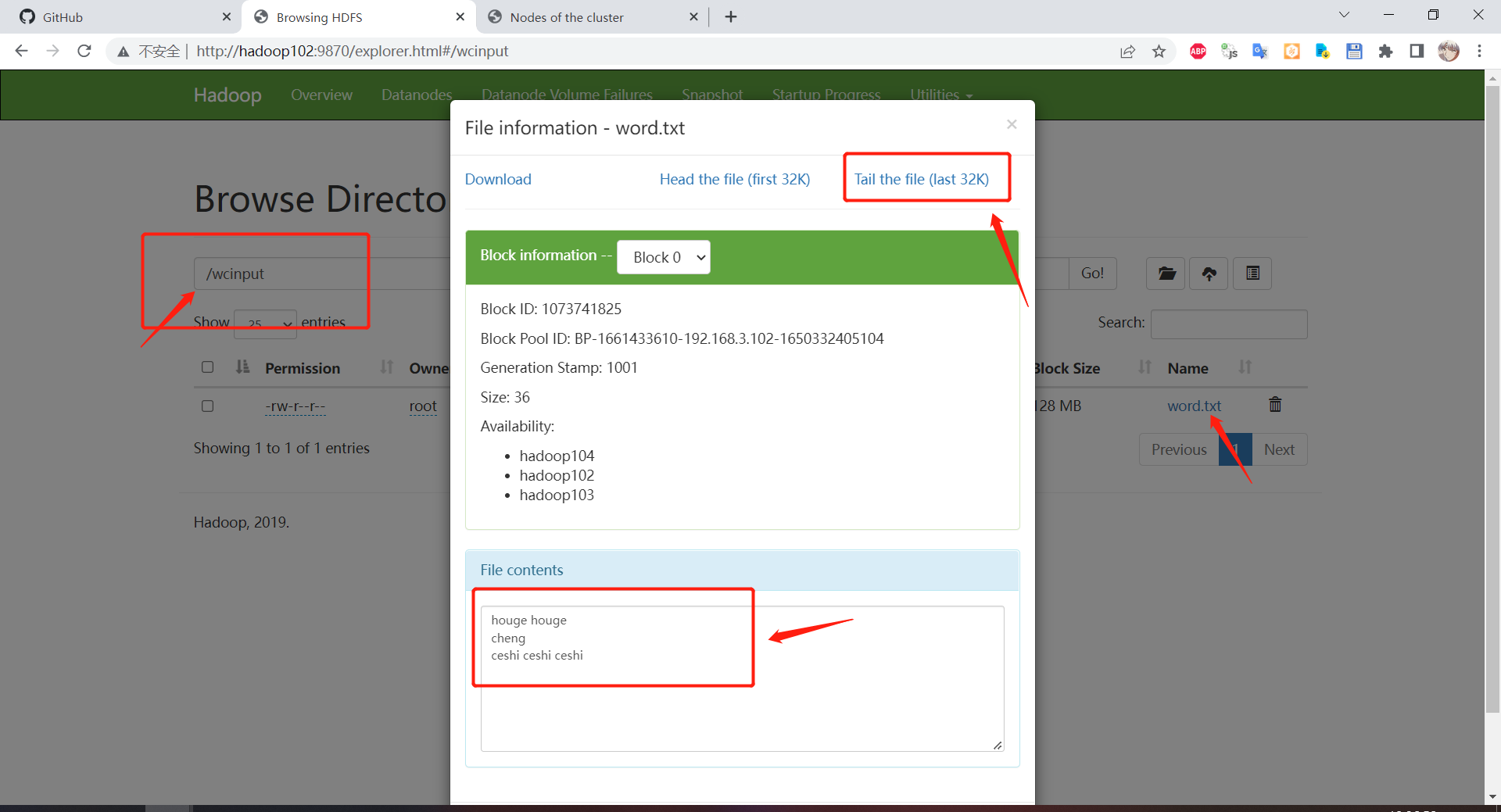
MapReduce 测试
cd /opt/module/hadoop-3.1.3
# 注意 /wcoutput 是结果输出目录,这个目录在 hdfs 上不能存在,程序会自己创建
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput上 web 端查看,可以看到有一个 wordcount 任务在跑:http://hadoop103:8088/cluster/apps/RUNNING
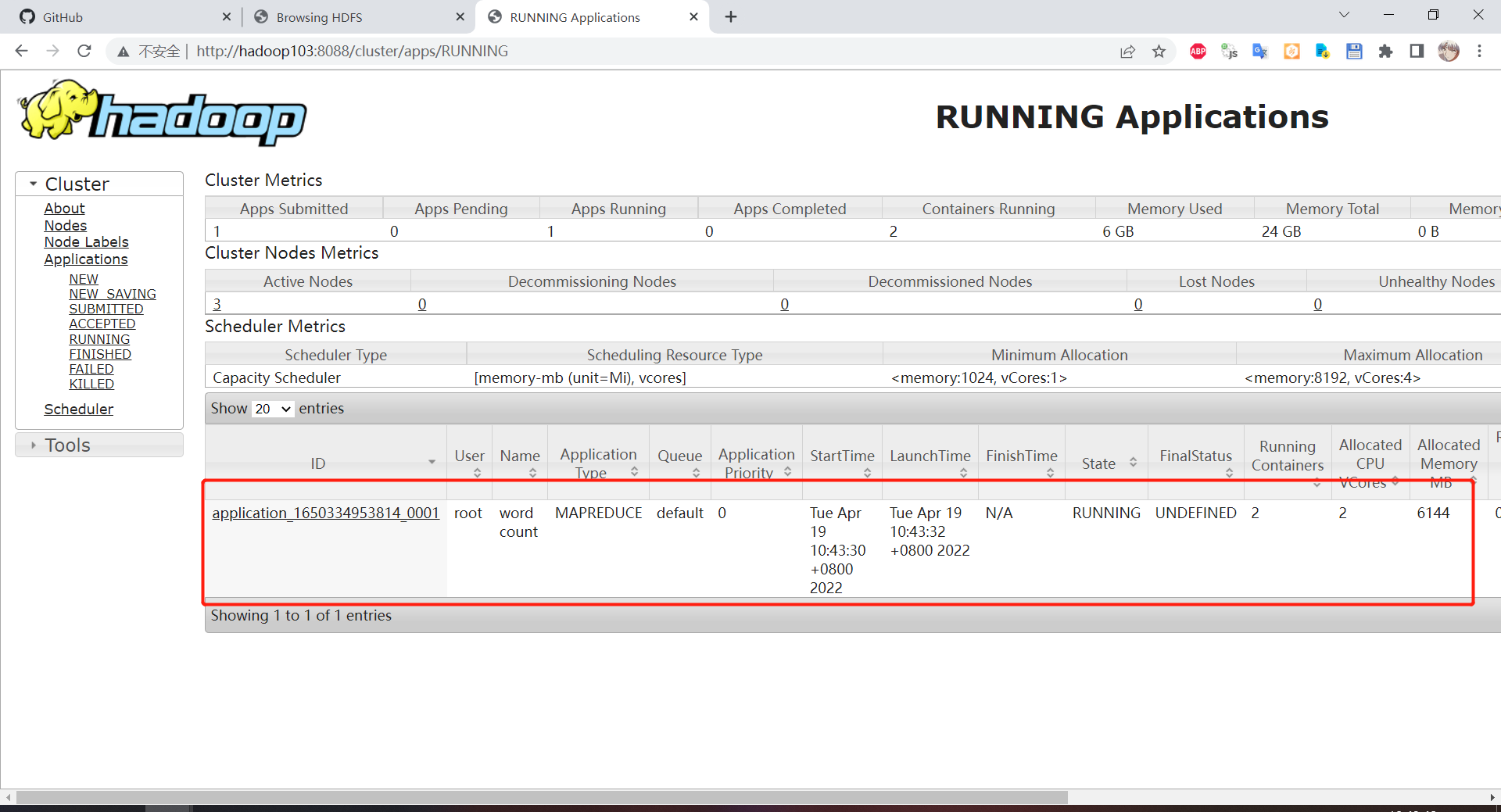
# 执行日志
2022-04-19 10:43:28,907 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.3.103:8032
2022-04-19 10:43:29,574 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1650334953814_0001
2022-04-19 10:43:29,713 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-19 10:43:29,973 INFO input.FileInputFormat: Total input files to process : 1
2022-04-19 10:43:30,023 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-19 10:43:30,104 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-19 10:43:30,155 INFO mapreduce.JobSubmitter: number of splits:1
2022-04-19 10:43:30,326 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-19 10:43:30,420 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1650334953814_0001
2022-04-19 10:43:30,420 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-04-19 10:43:30,700 INFO conf.Configuration: resource-types.xml not found
2022-04-19 10:43:30,701 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-04-19 10:43:31,208 INFO impl.YarnClientImpl: Submitted application application_1650334953814_0001
2022-04-19 10:43:31,279 INFO mapreduce.Job: The url to track the job: http://hadoop103:8088/proxy/application_1650334953814_0001/
2022-04-19 10:43:31,280 INFO mapreduce.Job: Running job: job_1650334953814_0001
2022-04-19 10:43:41,697 INFO mapreduce.Job: Job job_1650334953814_0001 running in uber mode : false
2022-04-19 10:43:41,699 INFO mapreduce.Job: map 0% reduce 0%
2022-04-19 10:43:50,951 INFO mapreduce.Job: map 100% reduce 0%
2022-04-19 10:44:00,224 INFO mapreduce.Job: map 100% reduce 100%
2022-04-19 10:44:01,259 INFO mapreduce.Job: Job job_1650334953814_0001 completed successfully
2022-04-19 10:44:01,402 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=42
FILE: Number of bytes written=434299
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=139
HDFS: Number of bytes written=24
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=25120
Total time spent by all reduces in occupied slots (ms)=22660
Total time spent by all map tasks (ms)=6280
Total time spent by all reduce tasks (ms)=5665
Total vcore-milliseconds taken by all map tasks=6280
Total vcore-milliseconds taken by all reduce tasks=5665
Total megabyte-milliseconds taken by all map tasks=25722880
Total megabyte-milliseconds taken by all reduce tasks=23203840
Map-Reduce Framework
Map input records=3
Map output records=6
Map output bytes=60
Map output materialized bytes=42
Input split bytes=103
Combine input records=6
Combine output records=3
Reduce input groups=3
Reduce shuffle bytes=42
Reduce input records=3
Reduce output records=3
Spilled Records=6
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=306
CPU time spent (ms)=2120
Physical memory (bytes) snapshot=445448192
Virtual memory (bytes) snapshot=10477551616
Total committed heap usage (bytes)=394264576
Peak Map Physical memory (bytes)=275689472
Peak Map Virtual memory (bytes)=5234483200
Peak Reduce Physical memory (bytes)=169758720
Peak Reduce Virtual memory (bytes)=5243068416
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=36
File Output Format Counters
Bytes Written=24可以清楚的看到分为了 map 和 reduce 计算
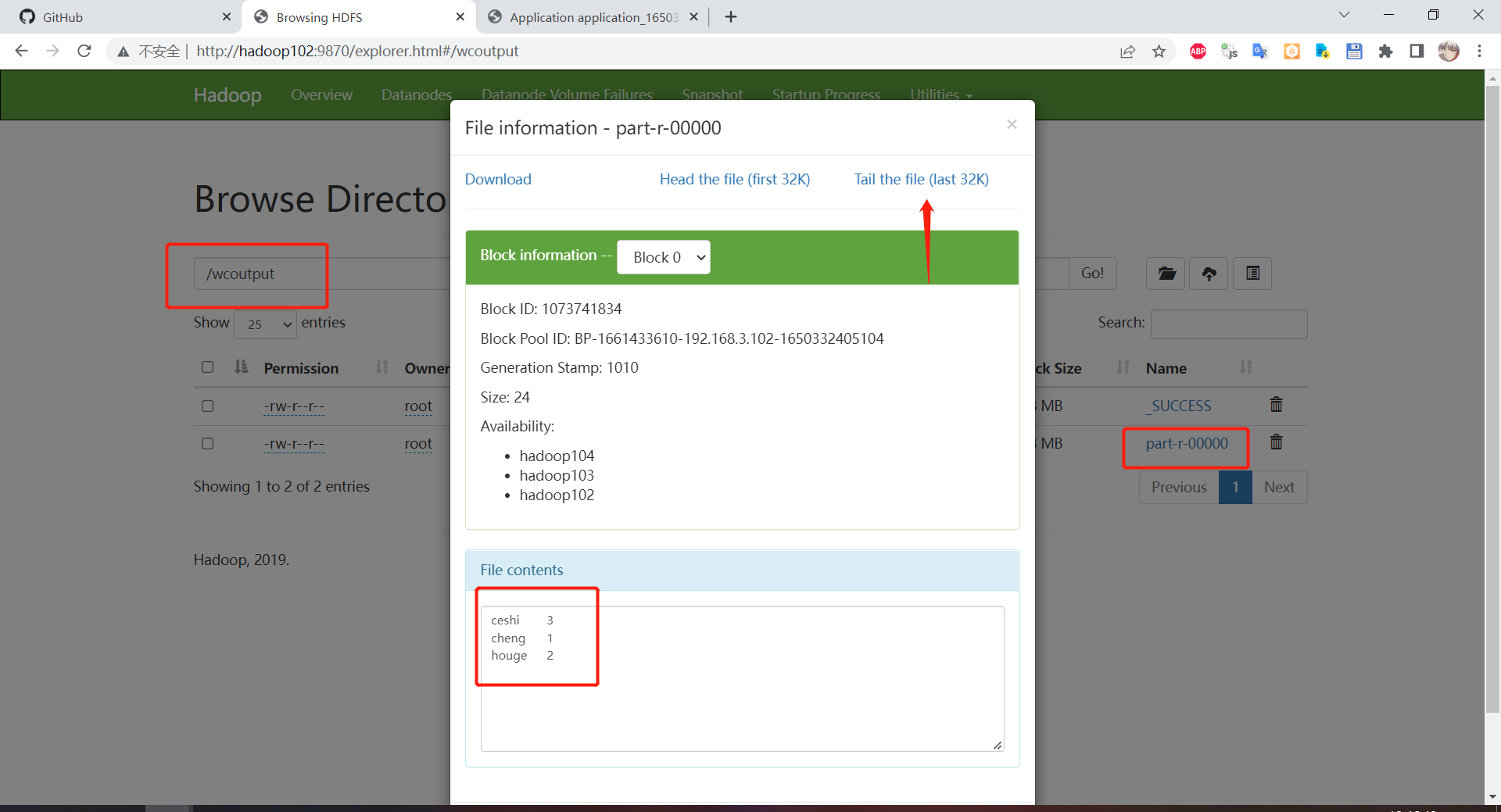
到 HDFS 上查看计算结果:
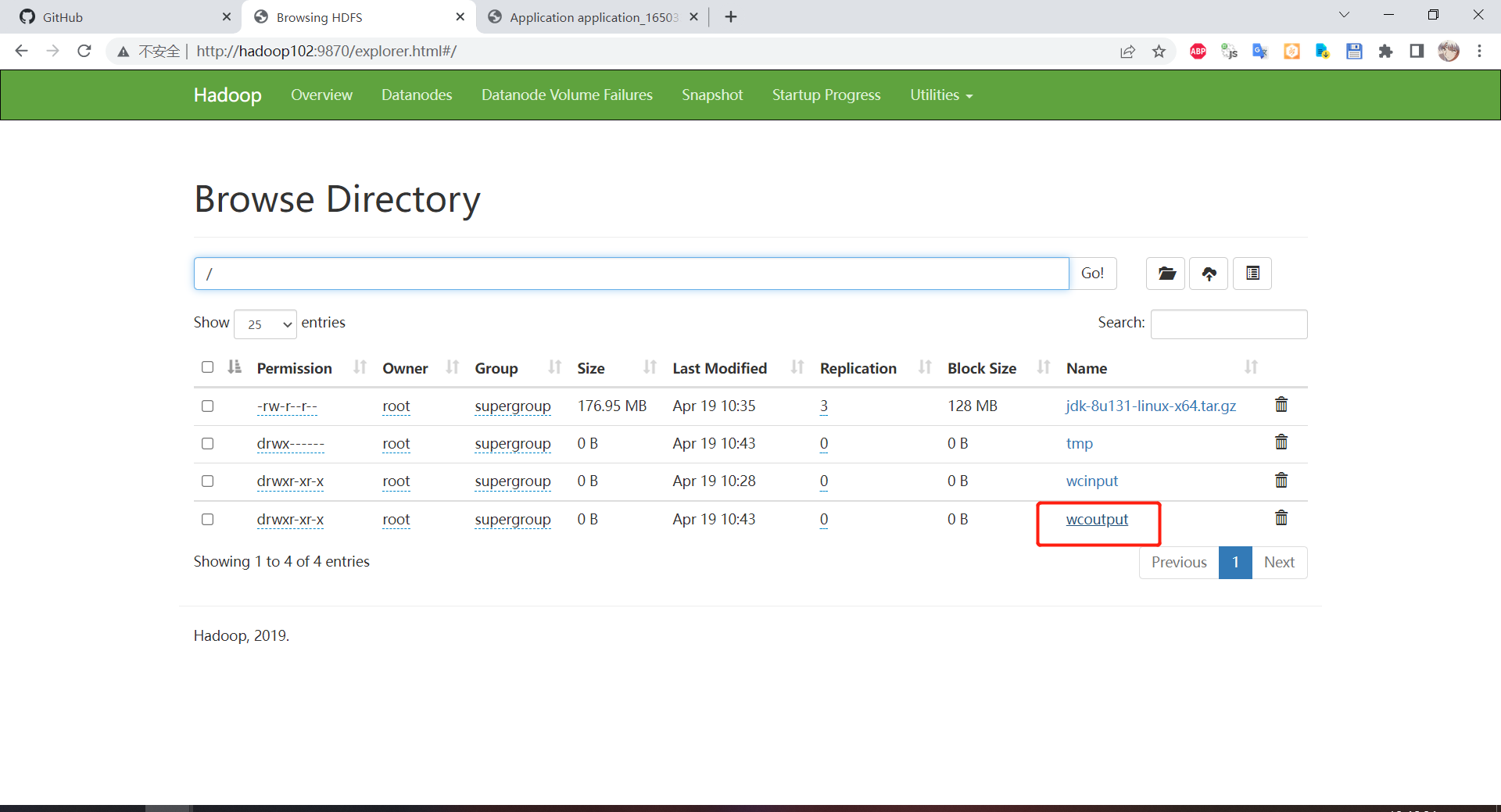
进入 wcoutput 可以看到已经词频统计完毕了,这个 SUCCESS 文件代表就是任务成功执行标志,没有其他意义,我们的结果文件在 part-r-00000 文件中