关于 Kafka 的集群搭建安装记录
Kafka 集群搭建
安装步骤
-
集群规划
hadoop102 hadoop103 hadoop104 zk zk zk kafka kafka kafka -
官方下载地址:Apache Kafka
关于 Kafka 版本的说明:kafka_2.12-3.0.0.tgz
2.12 代表 Scala 的版本,Kafka 的 broker 是用 Scala 写的
3.0.0 是 Kafka 的版本,Kafka 的 producer 和 consumer 是用 Java 写的
-
前置条件:
- 已经安装 JDK:Hadoop 集群搭建-JDK安装
- 已经安装 Zookeeper:Zookeeper 安装记录
-
压缩包上传至服务器,然后解压
[root@hadoop102 software]# tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/ -
进入解压缩后的目录
[root@hadoop102 kafka_2.12-3.0.0]# pwd /opt/module/kafka_2.12-3.0.0 [root@hadoop102 kafka_2.12-3.0.0]# ll 总用量 64 drwxr-xr-x. 3 root root 4096 9月 9 2021 bin drwxr-xr-x. 3 root root 4096 9月 9 2021 config drwxr-xr-x. 2 root root 8192 5月 16 20:51 libs -rw-r--r--. 1 root root 14521 9月 9 2021 LICENSE drwxr-xr-x. 2 root root 262 9月 9 2021 licenses -rw-r--r--. 1 root root 28184 9月 9 2021 NOTICE drwxr-xr-x. 2 root root 44 9月 9 2021 site-docs -
bin 目录下常用脚本
-
进入 config 下,进行一些必要的配置
[root@hadoop102 config]# vim server.properties# The id of the broker. This must be set to a unique integer for each broker. # 每个 broker 的唯一 id 千万不能和其他 broker 重复 broker.id=102 ############################# Log Basics ############################# # A comma separated list of directories under which to store log files # kafka 的运行日志(数据)存放的路径,这个路径不存在的话会自己创建 可以配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/opt/module/kafka_2.12-3.0.0/datas ############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. # Zookeeper集群地址 可以单机也可以集群 后面的 /kafka 是为了让 Kafka 单独用一个 zk 节点 zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka -
分发配置好的 kafka 包
xsync kafka_2.12-3.0.0/分发完毕立即上另外两台机器上修改 broker.id
-
配置环境变量
vim /etc/profile.d/my_env.sh # 写入以下内容 # KAFKA_HOME export KAFKA_HOME=/opt/module/kafka_2.12-3.0.0 export PATH=$PATH:$KAFKA_HOME/bin # 分发环境变量配置文件 xsync /etc/profile.d/my_env.sh # 在三台机器上分别执行 source /etc/profile -
启动集群
先启动 Zookeeper 集群,再启动 Kafka 集群
# zk.sh 是之前写的 Zookeeper 集群启停脚本 zk.sh start # 三台机器分别执行 在 kafka 的安装目录下 /opt/module/kafka_2.12-3.0.0 bin/kafka-server-start.sh -daemon config/server.properties # jps 验证 [root@hadoop102 kafka_2.12-3.0.0]# xcall jps =============== hadoop102 =============== 44604 Kafka 44749 Jps 125294 QuorumPeerMain =============== hadoop103 =============== 47090 Jps 6115 QuorumPeerMain 47052 Kafka =============== hadoop104 =============== 7893 QuorumPeerMain 105833 Jps 105807 Kafka集群启动成功
xcall 脚本是在三台机器分别执行相同的命令,脚本内容为
#!/bin/bash for host in hadoop102 hadoop103 hadoop104 do echo =============== $host =============== ssh $host $1 done -
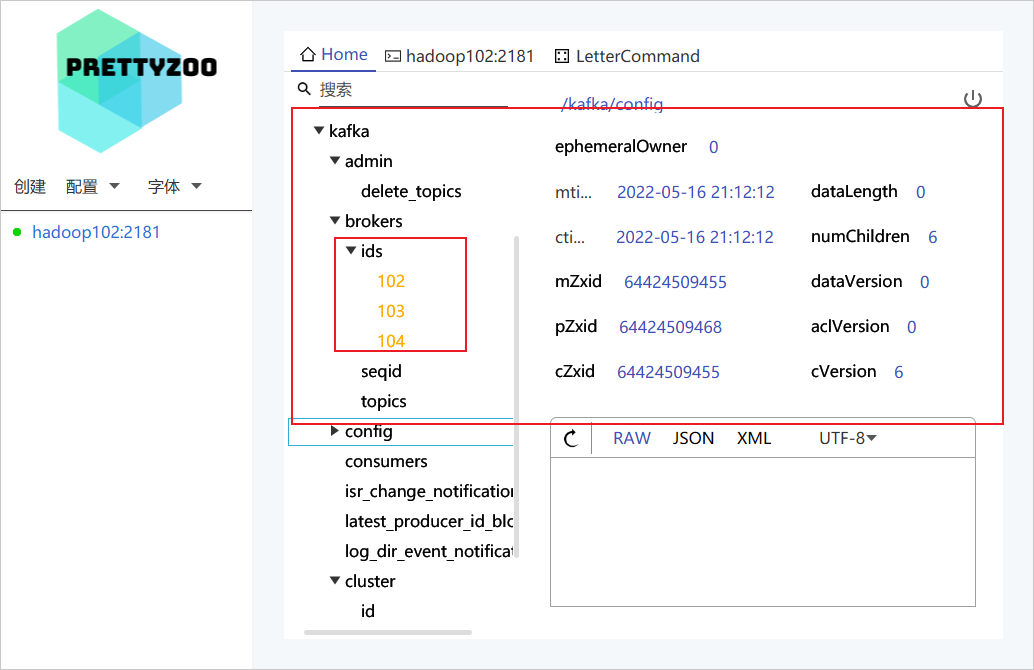
可以在 Zookeeper 上清除的看到自行配置的三个 broker id 信息
集群启停脚本
为了方便,编写 Kafka 集群统一启动及停止脚本
cd /usr/bin
vim kf.sh脚本内容
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka_2.12-3.0.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.12-3.0.0/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka_2.12-3.0.0/bin/kafka-server-stop.sh"
done
};;
esac这样启动停止集群就变成了
kf.sh start
kf.sh stop注意事项
- 启动 Kafka 集群之前,一定要先启动 Zookeeper 集群
- 停止 Kafka 集群,一定要先停止 Kafka 集群,再停止 Zookeeper 集群,因为 Kafka 集群停止需要用到 Zookeeper,如果 Zookeeper 先停了,Kafka 进程就去 Zookeeper 上找不到自己的信息了,从而无法停止,只能 Kill 掉进程来结束